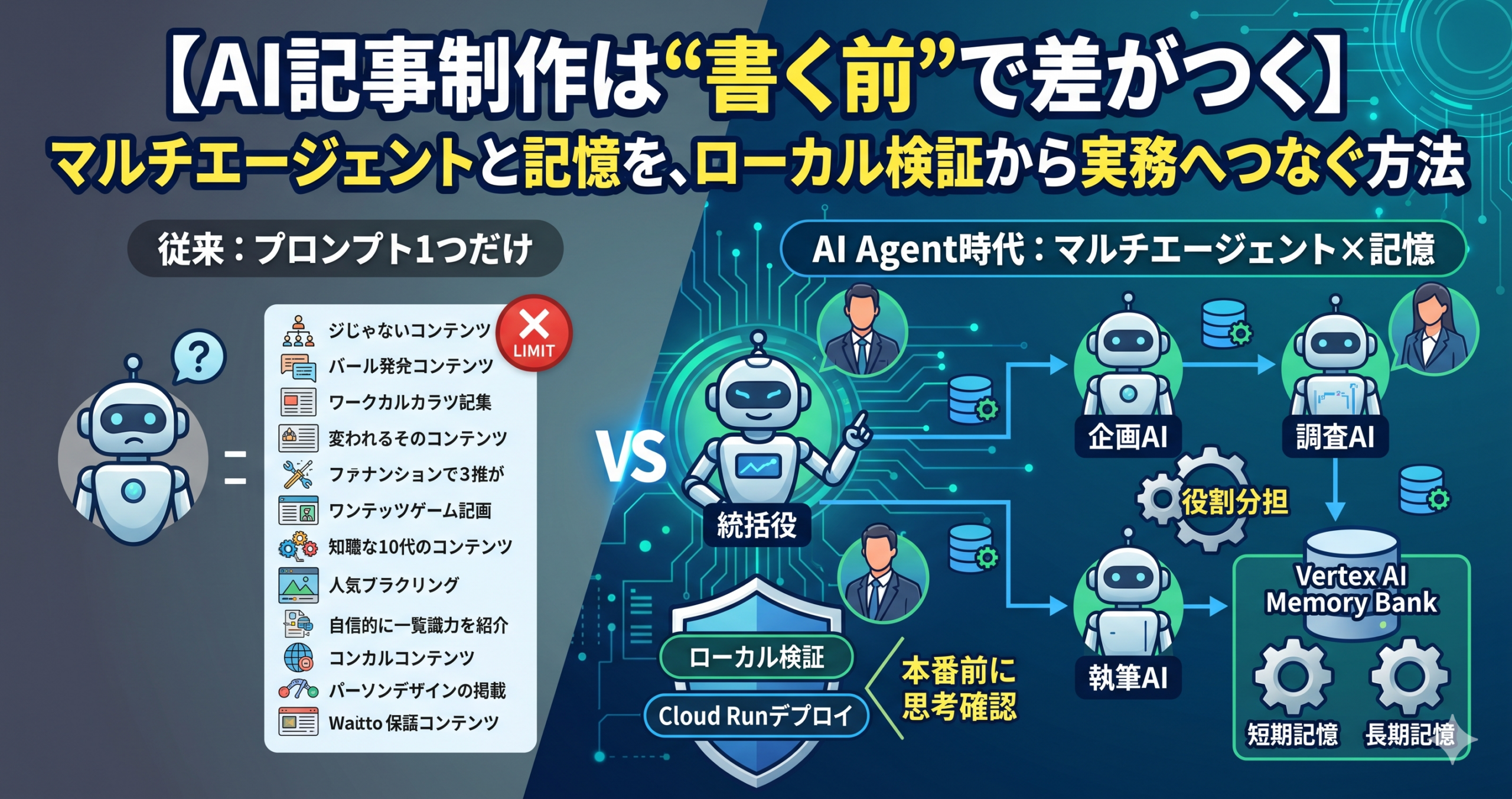
【AI記事制作は“書く前”で差がつく】マルチエージェントと記憶を、ローカル検証から実務へつなぐ方法
AIで記事制作や調査を自動化したいとき、つまずきやすいのはモデル性能そのものより、「複数エージェントが本当に連携するか」「前回の指示を覚えているか」「本番前にどこまで確かめるか」です。Google Cloudの開発者向け記事では、Google ADK、MCP、Vertex AI Memory Bankを使ったマルチエージェント構成を、まずローカルで検証し、その後にCloud Runへ進める流れが示されています。本記事ではその考え方を、日本のデジタルマーケ実務向けに再構成し、編集、ナレッジ活用、社内説明、運用ルールまでつながる形で整理します。 :contentReference[oaicite:1]{index=1}

-23-120x68.png)
要点サマリー
先に結論を示すと、マルチエージェント運用で重要なのは「何を作れるか」より、「どの役割を分け、何を記憶し、どこまで本番前に確認するか」を明確にすることです。
この記事で答える主な問い
- マルチエージェントとメモリは、そもそも何が違うのか
- ローカル検証は、何をどこまで確認するための工程なのか
- 編集部やマーケチームの運用に、どう置き換えられるのか
- 短期記憶と長期記憶をどう分けると失敗しにくいのか
- 小さく始めるなら、どの構成から入るのが現実的か
イントロダクション
AIで記事を作る仕組みは、一つのプロンプトだけではすぐ限界が見えます。特に実務では、調査、要約、執筆、修正反映を一人のAIに押し込むほど、品質のばらつきが大きくなりやすいです。
結論から言うと、マルチエージェント構成が役立つのは、AIを賢く見せるためではなく、作業分担と責任分担を明確にできるからです。Google Cloudの「Dev Signal」では、統括役が複数の専門エージェントを束ね、さらにVertex AI Memory Bankで過去の好みや指示を跨いで保持する構成が示されています。これにより、単発で賢い返答を狙うのではなく、継続的に“その人らしい出力”へ近づける考え方が取りやすくなります。 :contentReference[oaicite:6]{index=6}
今回の参照元では、本番のCloud Runデプロイへ進む前に、ローカル環境で推論、ツール連携、秘密情報、メモリ接続を確認する工程が重視されています。ここが重要なのは、実務で問題になるのが“モデルが答えられるか”だけではなく、“役割を跨いでも意図が崩れないか”“前回の指示を正しく再利用するか”だからです。ローカルでの検証は、単なる開発都合ではなく、品質保証の最初の壁と考えた方が分かりやすいです。 :contentReference[oaicite:7]{index=7}
デジタルマーケの現場に置き換えると、これは「記事案を出すAI」「一次調査をするAI」「ブランド文体に整えるAI」を分け、さらに“前回こういう表現は避けたいと指示した”ことを覚えさせる仕組みに近いです。単発生成を繰り返すより、役割と記憶を設計した方が、社内説明や品質管理がしやすくなります。
マルチエージェントは、AIを増やす話ではありません。編集フローの役割分担を、AIでも再現しやすくする設計だと捉えると理解しやすくなります。
- 一つのAIに全工程を任せるより、工程を分けた方が出力の理由を説明しやすくなります。
- 記憶は便利機能ではなく、継続運用時の品質安定化に関わる要素です。 :contentReference[oaicite:8]{index=8}
- ローカル検証は、コスト削減だけでなく、本番前の失敗を早めに見つけるための工程です。 :contentReference[oaicite:9]{index=9}
概要
まず整理したいのは、マルチエージェント、MCP、短期記憶、長期記憶、ローカル検証がそれぞれ何を担うのかです。
今回の中心論点は、「AIをどう賢くするか」ではなく、「役割、ツール、記憶、検証をどう分けるか」です。Google Cloudのシリーズでは、MCPで外部ツール接続を標準化し、ADKで複数エージェントを束ね、Vertex AI Memory Bankで長期記憶を持たせ、ローカル環境で動作を検証してから本番へ進む流れが示されています。 :contentReference[oaicite:10]{index=10}
マルチエージェント
役割の異なるエージェントを分け、統括役が順番や連携を管理する構成です。参照元の作例では、発見、調査、執筆といった専門役が置かれています。 :contentReference[oaicite:11]{index=11}
短期記憶
同じセッション内で、あるエージェントが得た情報を次のエージェントへ渡すための作業用記憶です。会話や処理の途中だけで使う前提です。 :contentReference[oaicite:12]{index=12}
長期記憶
ユーザーの好みや過去の指示をセッションをまたいで保持する仕組みです。Memory Bankは、特定のアイデンティティに紐づく形で記憶を保持します。 :contentReference[oaicite:13]{index=13}
従来は、長いプロンプトに全部を詰め込み、毎回“前回の前提”を再説明する運用になりがちでした。今回の構成では、作業途中で必要な情報は短期記憶へ、継続的に覚えるべき好みや履歴は長期記憶へ分けています。Google CloudのMemory Bank概要でも、これは静的なRAGの代替ではなく、時間とともに更新される文脈層として説明されています。 :contentReference[oaicite:14]{index=14}
| 観点 | 一つのAIにまとめる運用 | マルチエージェント+記憶の運用 |
|---|---|---|
| 役割分担 | 曖昧になりやすい | 担当が分かれて説明しやすい |
| 情報の受け渡し | 長いプロンプトに依存しやすい | 短期記憶で段階的に渡しやすい |
| 継続的な学習 | 毎回再指示が必要になりやすい | 長期記憶で好みを再利用しやすい |
| 品質検証 | 本番で気づきやすい | ローカルで先に崩れ方を確認しやすい |
- 短期記憶と長期記憶は混ぜない方が設計しやすくなります。 :contentReference[oaicite:15]{index=15}
- マルチエージェントは、役割の明確化が主目的です。
- ローカル検証は、本番前に“思考と道具の同期”を確認する工程として捉えると分かりやすいです。 :contentReference[oaicite:16]{index=16}
利点
この考え方の利点は、AI活用を“便利そうな実験”ではなく、役割と品質が見える運用へ変えやすいことです。
結論として、マルチエージェントと記憶を導入する利点は、出力の安定性そのものより、「なぜこの形で出たか」を説明しやすくなることにあります。編集、調査、レビューの役割を分けることで、属人的なAI運用から少し離れやすくなります。
記事制作のばらつきを抑えやすい
文体や粒度を長期記憶で反映しやすくなるため、毎回ゼロから指示し直す負担を減らしやすくなります。 :contentReference[oaicite:17]{index=17}
どこで崩れたかを見つけやすい
調査役、執筆役、統括役を分けると、どの工程で意図がずれたかを確認しやすくなります。
社内レビューに乗せやすい
役割ごとの責任を説明しやすいため、法務、編集長、営業などとの接続が作りやすくなります。
導入判断がしやすい
一つの万能AIを買う話ではなく、工程分解と品質保証の話として説明できるため、稟議にかけやすくなります。
とくにデジタルマーケの現場では、記事企画、競合調査、一次情報確認、社内文体反映、バナー文言調整などが分断されやすいです。こうした流れを一つのAIへ押し込むほど、責任の所在が曖昧になります。役割を分け、記憶の扱いを明示することで、AI導入の説明責任も持たせやすくなります。
編集部を持つ企業、オウンドメディア運営企業、社内ナレッジを記事や営業資料へ再利用したい会社、ブランドトーンの統一が重要な企業では、この構成を導入すると運用しやすくなります。
- 品質の再現性を高めたいチームに向いています。
- ナレッジの属人化を減らしたい組織とも相性がよいです。 :contentReference[oaicite:18]{index=18}
- AIを使う理由を、効率化だけでなく品質管理として説明しやすくなります。
応用方法
実務では、記事制作、ナレッジ整理、レビュー支援、社内QAの四つに分けて考えると応用しやすくなります。
応用で重要なのは、技術構成をそのまま導入することではなく、自社のフローを「発見」「調査」「整形」「記憶」に分けて見直すことです。ここまで分かれば、ツール選定より先に設計すべきことが見えやすくなります。
企画・調査・執筆を分ける
参照元の作例では、発見、技術的な調査、執筆の役割が分かれています。マーケ記事制作でも、話題抽出、一次情報確認、ブランド文体への整形を分けると、精度のばらつきを抑えやすくなります。 :contentReference[oaicite:19]{index=19}
- 企画出しと執筆を同じAIに押し込んでいないか
- 一次情報確認を別工程にできるか
- 文体調整を独立させられるか
- 人間レビューの入り口を明確にしているか
長期記憶を“嗜好”に限定して使う
Memory Bankは、ユーザーの嗜好や過去の重要事項を跨いで覚える用途に向いています。一方、毎回更新が必要な運用ルールや数値は、長期記憶へ曖昧に保存するより、別の信頼ソースで管理した方が安全です。 :contentReference[oaicite:20]{index=20}
- 覚えたいものは嗜好か、事実か
- 変わりやすい情報を長期記憶に入れすぎていないか
- 毎回参照すべき正式情報源が別にあるか
- 記憶の更新基準が決まっているか
ローカルで出力の崩れ方を観察する
Google Cloudの記事では、専用のテストランナーやローカル設定を通じて、クラウド上のMemory Bankも含めた一連の連携を検証しています。これは、出力の完成度を見るだけでなく、どのツールや記憶呼び出しで崩れるかを確認する意味があります。 :contentReference[oaicite:21]{index=21}
- ローカルで通しテストができるか
- 同じ質問で再現確認できるか
- メモリの呼び出しタイミングを確認できるか
- 本番に行く前に崩れ方を見られるか
短期記憶と長期記憶の境界を明確にする
短期記憶は同じ会話内で必要な作業情報の受け渡しに、長期記憶は個人の好みや繰り返し出る希望の保持に向いています。問い合わせ対応や営業支援でも、この境界を曖昧にしない方がトラブルを減らしやすいです。 :contentReference[oaicite:22]{index=22}
- 今だけ必要な文脈を長期記憶へ入れていないか
- 恒常的な好みだけを残す方針か
- 新規セッションで初期化される情報を理解しているか
- ユーザー単位の扱いが明確か
BtoBでは、記事だけでなく、提案書ドラフト、顧客向けFAQ、営業メモ整形、セミナー後のフォロー文面生成にも応用しやすいです。重要なのは、どの工程をAIに任せ、どこで人が責任を持つかを先に決めることです。
- 応用しやすいのは、工程が分かれている仕事です。
- 長期記憶は“何でも覚える箱”にしない方が運用しやすくなります。 :contentReference[oaicite:23]{index=23}
- ローカル検証は、品質保証の入り口として使う方が効果を感じやすいです。 :contentReference[oaicite:24]{index=24}
導入方法
導入は、設計、準備、運用、改善、ガバナンスに分けると進めやすくなります。最初から大きな自動化を目指すより、小さな工程分解から始める方が現実的です。
導入で最初に決めたいのは、「どの工程を分けると品質が安定するか」です。AIを何台使うかではなく、どこを統括役にし、どこを専門役にするかを先に決めると失敗しにくくなります。
役割を先に決める
調査、要約、執筆、レビューなど、自社の流れに沿って役割を切ります。技術記事でも、この役割分担が先に設計されています。 :contentReference[oaicite:25]{index=25}
秘密情報と環境差分を整理する
参照元では、ローカル用の環境変数を置き、本番ではSecret Managerやインフラ設定へ置き換える流れが示されています。ローカルと本番の差を最初に明確にした方が混乱を減らせます。 :contentReference[oaicite:26]{index=26}
ローカルで通しテストを回す
ADKのWeb Interfaceやテストランナーのように、会話、状態、イベント履歴を見ながら検証できる手段を持つと、本番前の不安を減らしやすくなります。 :contentReference[oaicite:27]{index=27}
設計で決めたい判断基準
設計では、各エージェントに「何を判断してよく、何を判断してはいけないか」を決めることが重要です。たとえば、調査役は一次情報の収集に集中し、執筆役は文体整形に集中する、といった形にすると品質が安定しやすくなります。
- 統括役は何を判断するか
- 専門役は何だけを担当するか
- 人間レビューはどこで入るか
- 短期記憶に何を置くか
- 長期記憶に何を残すか
準備でそろえたいチェック項目
| 領域 | 確認すること | よくある失敗 |
|---|---|---|
| 役割分担 | 統括役と専門役の境界が明確か | 全員が似た仕事をして責任が曖昧になる |
| 記憶設計 | 短期と長期の境界が決まっているか | 何でも長期記憶へ入れてしまう |
| ローカル検証 | 環境変数、ツール接続、イベント観察ができるか | 本番で初めて一連の流れを試す |
| 権限管理 | 誰がどの記憶を読めるか・書けるか | アクセス範囲を曖昧にする |
運用フローは短く、改善ループは明確にする
よくある失敗
一つのAIに全部任せる、長期記憶へ何でも保存する、ローカルで通し検証をしない、本番で初めて秘密情報や外部接続を試す、役割分担を決めないまま人数だけ増やす。このあたりは、導入初期に起きやすい典型例です。
最初に小さく始める方法
最初は、調査役と執筆役の二役構成でも十分です。そこに短期記憶だけを足し、長期記憶は“文体の好み”や“よく使う構成”のような限定的なものだけ保存するところから始めると、運用負荷を抑えやすくなります。ローカル検証では、まず同じ入力で再現性を見ることから始めると進めやすいです。
企画担当AIと執筆担当AIを分ける → 同一セッション内の受け渡しだけを実装する → ローカルで数本分の通し確認をする → 文体の好みだけ長期記憶へ入れる → 本番運用へ広げる、という順で始めると失敗しにくくなります。
- 設計では、役割分担を先に決めることが最優先です。
- 準備では、環境差分と秘密情報の扱いを明確にします。 :contentReference[oaicite:28]{index=28}
- 運用では、ローカルで通しの会話を観察できることが重要です。 :contentReference[oaicite:29]{index=29}
- 改善では、崩れた工程だけを直す考え方が有効です。
- ガバナンスでは、長期記憶のアクセス範囲を明確にするとぶれにくくなります。 :contentReference[oaicite:30]{index=30}
未来展望
未来を断定する必要はありません。ただ、AI活用が単発生成から継続運用へ移るほど、記憶と評価の重要性は高まりやすいです。
今後広がりそうなのは、AIの性能比較より、運用の再現性をどう持つかという競争です。ADKは、可視デバッグ、評価フレームワーク、Web Interfaceなど、実行経路そのものを確認する方向を強く打ち出しています。これは、出力を眺めるだけでなく、思考と手順を観察する運用が主流になりやすいことを示しています。 :contentReference[oaicite:31]{index=31}
また、Memory Bankの考え方が示すように、今後のAIは一回ごとの会話より、継続した関係の中で役立つことが期待されやすくなります。マーケ実務では、同じチームの文体、ブランド方針、好まれる構成、避けたい表現といった継続要素が多いため、長期記憶の扱いはさらに重要なテーマになりやすいです。 :contentReference[oaicite:32]{index=32}
評価が前工程に入る
出力後の感想ではなく、実行経路や状態を見ながら評価する運用が増えやすいです。 :contentReference[oaicite:33]{index=33}
長期記憶が差別化要素になる
継続運用の文体や嗜好の反映が、単発生成との差になりやすいです。 :contentReference[oaicite:34]{index=34}
ローカル検証が標準化しやすい
本番で試す前に、開発用画面やテストランナーで通し確認する流れは、今後さらに一般化しやすいです。 :contentReference[oaicite:35]{index=35}
役割を分けること、短期と長期の記憶を分けること、ローカルで通し検証すること。この三つは、モデルやUIが変わっても残りやすい基礎設計です。
- 未来を当てるより、運用の再現性を作る方が実務では重要です。
- 継続的なAI活用では、記憶の扱いが品質差になりやすいです。 :contentReference[oaicite:36]{index=36}
- 関連記事で深掘りするなら、社内ナレッジ設計、評価基準設計、ブランド文体の記憶運用がつながりやすいです。
まとめ
今回の論点を一言でまとめると、AI記事制作の品質は“生成力”だけでなく、“役割分担・記憶・検証”で決まりやすくなる、という整理がしやすくなります。
一言でまとめると、マルチエージェントと記憶の運用は、AIを増やす話ではなく、編集フローを設計し直す話です。Google Cloudの作例が示すように、統括役、専門役、短期記憶、長期記憶、ローカル検証を分けることで、継続的な品質安定化に近づきやすくなります。 :contentReference[oaicite:37]{index=37}
- マルチエージェントは、役割分担を明確にする設計として捉えると分かりやすいです。
- 短期記憶と長期記憶は、用途を分けた方が失敗しにくくなります。 :contentReference[oaicite:38]{index=38}
- ローカル検証は、本番前に推論・ツール・記憶の連携を確かめる工程です。 :contentReference[oaicite:39]{index=39}
- マーケ実務では、記事制作、社内ナレッジ整理、レビュー支援に応用しやすいです。
- 導入は、小さな役割分担から始め、記憶は限定的に使う方が現実的です。
次の小さなアクションとしては、まず今の制作フローを「企画」「調査」「執筆」の三つに分け、そのうちどこをAIで分担させると品質が安定しそうかを見直すのがおすすめです。そのうえで、同一セッション内の短期記憶だけを先に試し、長期記憶は文体や好みの保持から始めると、無理なく前進しやすくなります。
- 今の制作工程を三つに分ける
- 役割分担を一つ決める
- 短期記憶だけで通しテストする
- 文体の好みだけ長期記憶へ入れる
- ローカル検証を定例化する
FAQ
初心者がつまずきやすい疑問と、中級者が判断に迷いやすい論点を混ぜて整理しています。
FAQで大切なのは、正解を一つに決めることではなく、何を分けて考えると実務判断しやすいかを示すことです。
マルチエージェントは、AIをたくさん増やせばよいという意味ですか?
そうではありません。役割が曖昧なまま増やしても、責任分界がぼやけやすくなります。まずは工程を分け、その工程ごとに役割を置く考え方が重要です。
短期記憶と長期記憶は何が違いますか?
短期記憶は同じセッション内で必要な作業情報の受け渡し、長期記憶はユーザーの好みや履歴を跨いで覚える用途に向きます。混ぜると管理しにくくなります。 :contentReference[oaicite:40]{index=40}
ローカル検証は開発者向けだけの話ではないですか?
実務的にも重要です。本番で初めて役割連携や記憶呼び出しを試すと、品質崩れの原因が見つけにくくなります。ローカル検証は品質保証の入口として考えた方が分かりやすいです。 :contentReference[oaicite:41]{index=41}
長期記憶には何でも保存してよいですか?
あまりおすすめしません。好みや継続的な方針のように、跨いで残す価値が高いものに限定した方が運用しやすくなります。変わりやすい事実は別の信頼ソースで管理する方が安全です。 :contentReference[oaicite:42]{index=42}
マーケチームなら、どの業務から始めるとよいですか?
記事制作やFAQ整備のように、調査と文体調整が分かれている仕事から始めると手応えを感じやすいです。いきなり全面自動化を狙うより、二役構成で試す方が現実的です。
ADKのWeb Interfaceはそのまま本番で使えますか?
公式ドキュメントでは、ADK Webは開発とデバッグ向けであり、本番用途ではないと明記されています。検証手段として使い、本番は別の構成で考える必要があります。 :contentReference[oaicite:43]{index=43}
RAGがあればMemory Bankは不要ですか?
役割が異なります。Memory Bankは、静的な知識検索より、ユーザーごとの継続的な文脈保持に向いていると公式に説明されています。どちらか一方で置き換えるより、用途を分けた方が分かりやすいです。 :contentReference[oaicite:44]{index=44}
最初のPoCで何を成功条件にするとよいですか?
時間短縮だけより、文体の安定、一次調査の抜け漏れ削減、レビュー修正の減少のように、品質面でも成功条件を置く方が継続判断しやすくなります。
- FAQは、用語の説明だけでなく判断軸を示す形にすると役立ちやすいです。
- 実際の相談文に近い問い方にすると、検索意図との接続が自然になります。
- 関連記事で補足するなら、社内ナレッジ設計、レビュー基準、AI導入ガバナンスが自然につながります。
参考サイト
本文で扱った論点の確認用として、中心記事と関連する公式ドキュメントをまとめています。
今回の中心はGoogle Cloudのシリーズ記事ですが、実務に落とすにはMemory BankとADKの公式ドキュメントもあわせて見ると整理しやすくなります。
- Google Cloud Blog「Create Expert Content: Local Testing of a Multi-Agent System with Memory」
- Google Cloud Blog「Create Expert Content: Building Capabilities for a Multi-Agent System with Google ADK, MCP, and Cloud Run」
- Google Cloud Blog「Create Expert Content: Architect A Personalized Multi-Agent System with Long-Term Memory」
- Google Cloud Documentation「Vertex AI Agent Engine Memory Bank Overview」
- Agent Development Kit「Use the Web Interface」
本記事は一般的な実務整理を目的とした内容です。実際の導入では、社内ナレッジの性質、ブランド方針、法務・セキュリティ要件、レビュー体制、運用対象業務に応じて役割分担と記憶方針を調整してください。

「IMデジタルマーケティングニュース」編集者として、最新のトレンドやテクニックを分かりやすく解説しています。業界の変化に対応し、読者の成功をサポートする記事をお届けしています。