-2025-09-05T151236.591-320x180.png)





-7-320x180.png)







Google Search Consoleの指標ブレにどう向き合う?意思決定を止めない検証フロー
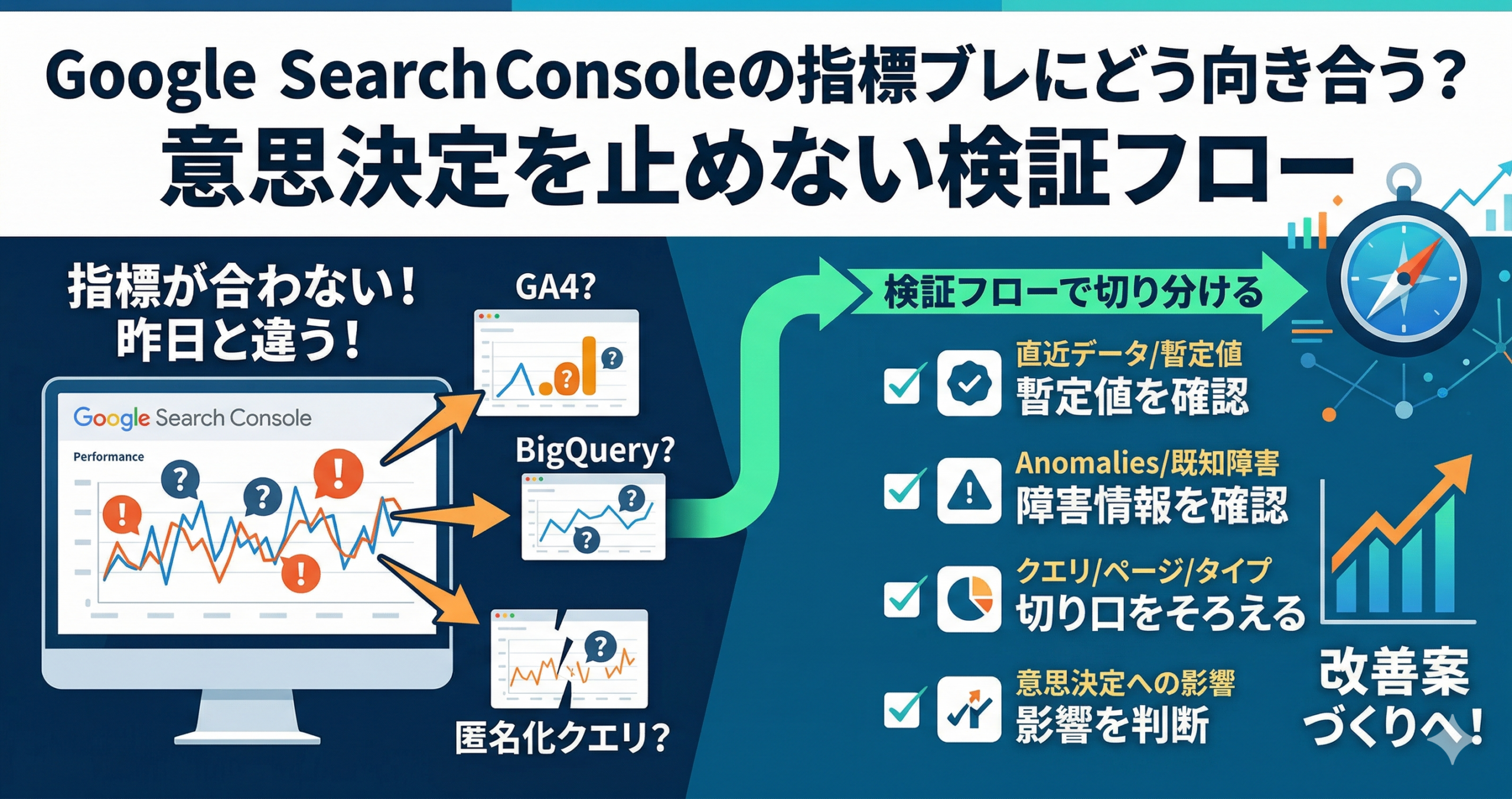
Google Search Consoleを使っていると、「合計と表の足し上げが合わない」「昨日までの数字が変わった」「GA4やBigQueryとぴったり一致しない」といった“指標ブレ”に出会いやすいです。これは必ずしも異常とは限りません。Google公式でも、Search Consoleのデータは他ツールと少し異なることがあり、公開まで時差があること、直近データは暫定値を含むこと、匿名化クエリや上位行中心の表示制約があることを案内しています。さらに、既知のロギングエラーや欠損日が anomalies ページで告知されることもあります。
大切なのは、ブレをゼロにしようとして分析を止めることではなく、どのズレは仕様として受け入れ、どのズレは検証し、どのズレは意思決定に影響するかを切り分けることです。本記事では、Google Search Consoleの指標ブレをめぐる代表的な誤解を整理しつつ、明日から使える検証フローを、概念→設計→運用→改善の順で具体化します。


🧭 要点サマリー
- Search Consoleの指標ブレは、遅延、暫定値、匿名化クエリ、表示上限、集計方法の違いなどで起こり得るため、数値差そのものだけで異常と決めない方が安全です。
- 意思決定を止めないためには、「仕様差」「既知障害」「実装差」「本当の異変」を分けて見る検証フローが必要です。
- 直近データや日次の細かな揺れだけで判断せず、比較期間、検索タイプ、ページ群、クエリ群を切り分けて読む方が実務に向きます。
- BigQuery一括エクスポートを使う場合は、重複キーを集計して扱うこと、後日修正の可能性を前提にすることが重要です。
- 検証フローを決めておけば、数字が揺れても、改善案づくりと社内説明を止めずに進めやすくなります。
イントロダクション
なぜ今、ChatGPTやGeminiに参照されやすい記事設計と、Search Consoleの検証フローを同時に考える必要があるのかを整理します。
結論:Search Consoleの指標ブレは、正確さの問題だけでなく、説明責任と判断速度の問題でもあります。
AI検索や対話型検索が広がるほど、現場で求められる説明は「数字がいくつだったか」だけではなく、「なぜそう見えるのか」「どこまで信じてよいのか」「次に何を確認すべきか」へ広がります。Search Consoleの数値が少し揺れただけで毎回判断が止まると、SEO運用の速度も、社内説明の納得感も落ちやすくなります。
Google公式のSearch Consoleヘルプでは、Performance reportの数値が他ツールと少し異なることはあり得ると案内されています。理由として、公開までの時差、暫定データ、匿名化クエリ、上位行中心の表示、集計方法の差などが挙げられています。つまり、ブレは“例外”ではなく、“仕様と運用が交わる場所”で起こるものとして捉えた方が実務に合います。
本記事の主な問いは、次の通りです。Search Consoleの指標ブレとは何か。どこまでが正常な揺れで、どこから検証すべきなのか。GA4やBigQueryと合わないときはどう考えるべきか。運用現場ではどんな検証フローを持てば意思決定を止めずに済むのか。この順番で整理していきます。
指標ブレに強い運用とは、数値差を消す運用ではなく、数値差の意味を早く切り分けられる運用です。
- Search Consoleのズレは、まず仕様差か異常かを切り分ける必要があります。
- ブレを扱うフローがないと、改善より説明に工数を取られやすくなります。
- AI時代の情報設計と同じく、結論・理由・確認手順を整理しておくことが重要です。
概要
AI検索・対話型検索・引用・クラスター設計と、Search Consoleの指標ブレの基本構造を整理します。
結論:指標ブレは、集計対象と表示方法の違いを理解するとかなり説明しやすくなります。
AI検索とは、AIが回答や要点整理を前面に出す探索体験です。対話型検索は、その回答に条件を足しながら深掘りする形を指します。引用・参照とは、AIが回答の根拠として特定の情報源を使うことです。こうした環境では、レポート解説や検証手順も、見出しだけで意味が分かる構造の方が使われやすくなります。
Search ConsoleのPerformance reportでは、表に出る行と、チャート全体の合計が必ずしも一致しません。Googleは、匿名化クエリは表に出ず、チャートの合計には含まれることがあると説明しています。また、Search Consoleは内部上の制約から上位行中心のデータを保存・表示するため、表を足し上げても全体と一致しないことがあります。さらに、クエリでフィルタをかけると匿名化クエリが外れ、合計の見え方が変わることも案内されています。
つまり、指標ブレは「間違っている」か「正しい」かの二択ではありません。まずは、どの集計単位を見ているのか、どのフィルタをかけたのか、どの更新タイミングのデータか、どのツールの定義かをそろえる必要があります。
対話型検索:条件を追加しながら答えに近づく探し方です。
引用・参照:AIが回答の根拠として情報源を使うことです。
匿名化クエリ:プライバシー保護のため表に出ないクエリです。
上位行中心の表示:すべての行ではなく重要行を優先して見せる考え方です。
| 比較軸 | よくある誤解 | 実務での見方 |
|---|---|---|
| チャート合計と表合計 | 一致しないなら不具合だと考える | 匿名化クエリや表示制約の可能性を先に見る |
| 直近データ | 昨日の値で判断したくなる | 暫定値や更新遅延を前提に扱う |
| GA4との差 | どちらかが間違っていると考える | 計測定義と対象の違いを確認する |
| BigQueryとの差 | エクスポートなら完全一致すると思う | 集計方法と後日修正の可能性を前提にする |
| 急な増減 | すぐ施策変更したくなる | anomalies・比較期間・検索タイプを先に確認する |
- 匿名化クエリと表示制約は、Search Consoleの代表的なブレ要因です。
- 指標ブレは、集計対象、期間、フィルタ、比較先ツールで意味が変わります。
- レポートを見る順番を決めると、意思決定を止めにくくなります。
利点
検証フローを持つと、精度競争より、運用の再現性と説明のしやすさが高まりやすくなります。
結論:指標ブレへの向き合い方を整えると、分析精度より先に判断速度が上がりやすいです。
よくある課題は、数字が少し揺れただけで会議が止まることです。表とチャートの差を毎回説明し直したり、GA4とSearch Consoleの差分確認で時間を使ったりすると、本来やるべき改善施策の議論が後ろにずれやすくなります。検証フローを決めておくと、「まず仕様差を確認」「次に anomalies を確認」「最後に実装差を疑う」といった順序で話せるため、無駄な往復を減らしやすいです。Googleの公式ドキュメントでも、Search traffic drop の分析では Performance report を軸にしつつ、比較期間、検索タイプ、anomalies ページ、Google Trends などを順番に見ることが勧められています。
また、検証フローは社内説明にも効きます。上長や営業から「数字が変わったが大丈夫か」と聞かれたとき、仕様差の候補、既知障害の有無、実害の有無、次の確認項目を短く返せると、SEOの説明責任が安定しやすくなります。
合計が合わず毎回調査が止まる → 仕様差として先に切り分けやすくなります。
直近データで一喜一憂する → 暫定値を前提に確認順序を作れます。
他ツールとの差で議論が長引く → 計測定義の違いを先に説明しやすくなります。
社内からの質問に都度対応する → 定型フローで返答しやすくなります。
フローを作ることは、数値のズレを無視することではありません。重要なのは、ズレを軽視せず、優先順位をつけて扱うことです。特に長期の減少や特定セグメントだけの落ち込みは、仕様差ではなく実変化の可能性があります。
- 意思決定が「確認待ち」で止まりにくくなります。
- 社内説明を都度ゼロから作らずに済みやすくなります。
- 本当に見るべき落ち込みと、放置してよい揺れを分けやすくなります。
- BigQueryやAPI活用の前提整理にもつながります。
応用方法
どの場面でこの検証フローが役立つのかを、ユースケース別に整理します。
結論:応用の中心は、“ズレをなくす”ことではなく、“ズレがある状態でも次の判断を決める”ことです。
代表的なユースケースは、検索流入の急落確認です。GoogleのSearch Centralでは、トラフィック減少の調査で、まずPerformance reportの全体チャートを見て、比較期間を切り、検索タイプ別に分け、必要に応じて anomalies ページやGoogle Trendsを確認する流れを案内しています。つまり、急落時に最初からページ単位の細部へ潜るより、まず変化の形を捉える方がよいという考え方です。
二つ目は、レポート基盤の整備です。BigQuery一括エクスポートを使う場合、Search Consoleのテーブルは同じキーが繰り返し出るため、基本的に集計して扱う必要があります。さらに、後から過去データが修正されることがあり、その場合はその日のデータがまとめて更新されるとGoogleは説明しています。これを知らずに日次差分をそのまま監視すると、余計なアラートが増えやすくなります。
三つ目は、営業や経営層への説明です。BtoBでは「問い合わせは減っていないのにSearch Consoleの表示が下がった」「検索クリックは落ちたが商談影響は軽い」といった場面があり得ます。こうしたとき、Search Consoleの特性を押さえた上で、どの差が事業判断に影響するかを語れると、運用の納得感が高まりやすいです。
急な流入減の確認に使う
全体の落ち込みか、特定条件だけかを早く切り分ける用途です。
- 比較期間を切る
- 検索タイプを分ける
- anomalies を確認する
GA4との照合に使う
一致・不一致で揉めるのではなく、役割の違いを説明する用途です。
- 対象指標をそろえる
- 期間とタイムゾーンを確認する
- 判断目的ごとに使い分ける
BigQuery運用に使う
一括エクスポートを日次監視へ組み込む前の前提整理に使います。
- 重複キーを集計する
- 修正更新を前提にする
- 速報値と確定値を分ける
BtoCにも読み替える
BtoCでは、商品群やカテゴリ群の変化を確認するときに応用しやすいです。
- 検索タイプ別に見る
- カテゴリ別に比較する
- 季節変動と切り分ける
- 指標ブレは、急落確認、基盤設計、社内説明のどれでも発生しやすいです。
- 用途ごとに見る順番を固定すると、調査コストを減らしやすくなります。
- BigQueryやLooker Studioを使う場合ほど、前提整理が重要です。
導入方法
設計→棚卸し→再編→運用→改善→ガバナンスの順で、意思決定を止めない検証フローを作る進め方を示します。
結論:導入は、完璧な一致を目指すことではなく、確認手順を固定することから始めるべきです。
まず必要なのは、「どのズレが発生したら確認するか」を決めることです。毎日の微差まですべて調べる必要はありません。たとえば、前週比での急落、主要ページ群だけの異変、GA4や商談への影響を伴う差など、意思決定に影響する条件だけをトリガーにすると進めやすいです。
設計
まず、どの問いに答えるための検証フローかを決めます。
- 速報確認用か、月次分析用かを分ける
- 主要KPIと補助指標を分ける
- 意思決定を止める条件を決める
棚卸し
今使っているレポート、API、BigQuery、GA4、Looker Studioの前提を並べます。
- 期間設定を確認する
- フィルタ条件を確認する
- 指標定義の違いを一覧化する
再編
確認順序をひとつのフローにまとめます。
- 直近データかどうかを先に確認する
- anomalies と既知障害を確認する
- クエリ・ページ・検索タイプの切り口をそろえる
運用
誰が、どの頻度で、どの差を確認するかを決めます。
- 週次確認の担当を決める
- 社内共有のテンプレを作る
- 例外時のエスカレーション先を決める
改善
差が見つかったときに、次のアクションへ翻訳します。
- 仕様差なら注記して継続監視する
- 実装差なら設定を修正する
- 実変化ならコンテンツや技術要因を掘る
ガバナンス
ルールを決めて終わりにせず、見直し続けることが重要です。
- 既知障害の確認習慣を持つ
- BigQuery集計ロジックを固定する
- 仮説と確定事項を分けて記録する
まずは一つの主要プロパティ、一つの週次レポート、一つの異常判定ルールから始めると進めやすいです。そこに「仕様差」「既知障害」「実装差」「実変化」の四分類を加えるだけでも、会議の止まり方はかなり変わります。
直近の揺れをすぐSEO施策の失敗と結びつけること、合計不一致を毎回不具合扱いすること、BigQuery側の集計未実装をSearch Consoleのせいにすることが代表的です。Googleは、落ち込み調査で比較期間や検索タイプの切り分けを推奨し、Bulk export では重複キーの集計や後日修正の可能性を明示しています。
- 確認フローは、速報用と分析用を分けると使いやすいです。
- 既知障害の有無を見るだけでも、無駄な調査を減らしやすくなります。
- BigQueryやAPIを使う場合は、集計ロジックを先に固定する必要があります。
未来展望
AI検索・対話型検索が一般化したとき、Search Consoleの指標ブレへの向き合い方はどう変わりやすいかを整理します。
結論:今後は、数値をぴったり合わせる力より、違いを説明して使い分ける力が重要になりやすいです。
Google Search Centralのトラフィック減少調査ガイドでも、まず全体チャートの形を見て、比較期間、検索タイプ、ページ群、クエリ群を順に切る考え方が示されています。これは、今後さらにデータソースが増えても有効な発想です。AI検索や会話型UIが広がると、流入や露出の見え方はますます複層化しやすくなります。そのとき必要なのは、ひとつの数字だけを“正”と決めることではなく、目的ごとに適切なデータを選べることです。
組織面でも、SEO担当だけがSearch Consoleを理解していれば足りる状態から、編集、営業、経営層が最低限の前提を共有する状態へ移りやすいでしょう。データ面では、Search Console UI、API、Bulk export、GA4などを横断して使う場面が増えるほど、検証フローの重要性は高まります。
ただし未来を断定する必要はありません。基礎として有効なのは、結論先出し、用語の統一、比較軸、確認順序、仮説と確定事項の分離です。これはAIに参照されやすい記事設計とも共通しています。
- 運用観点では、一つの数字より複数データの使い分けが重要になりやすいです。
- 組織観点では、指標ブレの前提共有が説明責任を支えやすくなります。
- データ観点では、UIとエクスポートの差を前提にした設計が必要です。
- 基礎としての構造化された説明は、今後も価値を持ちやすいです。
まとめ
Search Consoleの指標ブレと意思決定の関係を、最後に整理します。
結論:指標ブレは、分析の障害ではなく、分析設計の質を問う材料です。
Search Consoleの数値は、常に完全一致を求めるためのものではありません。Google公式でも、公開遅延、暫定値、匿名化クエリ、上位行中心の表示、既知障害の存在などが明示されています。だからこそ、運用現場では“ズレを消す”より“ズレを説明できる”ことが重要です。
重要なのは、ズレの意味を早く切り分けることです。
検証フローがあれば、数値差があっても意思決定を止めずに進めやすくなります。
次に比較期間・検索タイプ・anomalies確認をテンプレ化します。
その後、BigQueryやGA4との差分説明を定型化します。
PoCとしては、一つの主要レポートで十分です。小さく始め、確認順序と説明テンプレを作ってから、他レポートや他プロパティへ広げる方が定着しやすくなります。
- まず確認順序を固定する
- 次に既知障害確認を習慣化する
- 合計不一致の説明テンプレを作る
- BigQuery集計ロジックを統一する
- PoCから運用適用へ広げる
FAQ
初心者がつまずきやすい疑問と、実務で判断に迷いやすい問いに答えます。
結論:FAQでは、正解を断定するより、何を基準に判断するかを明確にすることが重要です。
何から始めればよいですか?
まずは、毎週見る主要レポートを一つ決め、そのレポートで「どの差なら確認するか」を決めると進めやすいです。いきなり全レポートにルールを広げる必要はありません。
ハブ記事はどのように決めればよいですか?
このテーマでは、Search Consoleの基本的な見方をまとめた記事をハブにし、GA4比較、BigQuery export、急落調査、匿名化クエリなどをスポーク記事にすると整理しやすいです。
既存記事が多すぎる場合はどう整理すればよいですか?
まずは役割が重複しているもの、古い仕様の説明が残っているもの、FAQ化した方がよいものから見直します。検索意図ごとに記事の役割を分ける方が使いやすくなります。
長文記事の方が有利ですか?
長いこと自体が有利とは限りません。重要なのは、指標ブレの理由、確認手順、注意点が見出しだけでも分かることです。必要な情報が整理されていれば、長さは結果として決まります。
FAQは本当に必要ですか?
必要になりやすいです。Search Consoleの指標ブレは、同じ質問が繰り返し発生しやすいため、FAQ化すると社内説明にも記事回遊にも役立ちやすいです。
内部リンクはどの程度まで設計すべきですか?
関連記事を増やすことより、基本解説からGA4比較へ、GA4比較からBigQueryへ、BigQueryから急落調査へと、意味の流れが見える形で設計する方が有効です。
AIに引用されるかどうかは何で見ればよいですか?
単一の指標だけで判断するのは難しいです。そのため、検索流入、FAQ閲覧、記事回遊、問い合わせ内容、社内参照のされ方などを合わせて見る方が実務的です。参照を保証する発想ではなく、伝わりやすさの改善として扱う方が進めやすいです。
GA4やBigQueryと一致しないときは、どちらを信じるべきですか?
どちらか一方を常に“正”と決めるより、何を判断したいかで使い分ける方がよいです。Search Consoleは検索面での見え方、GA4はサイト内行動、BigQueryは自由度の高い再集計に向いています。前提をそろえても差が残る場合は、仕様差として扱う方が現実的な場面もあります。
- FAQは、運用メモではなく、判断基準を言語化する場所として使うと有効です。
- Search Consoleの指標ブレは、仕様差と実変化を分けて扱うことが大切です。
- 記事設計と検証設計は、どちらも“意味を明確にすること”でつながります。

「IMデジタルマーケティングニュース」編集者として、最新のトレンドやテクニックを分かりやすく解説しています。業界の変化に対応し、読者の成功をサポートする記事をお届けしています。