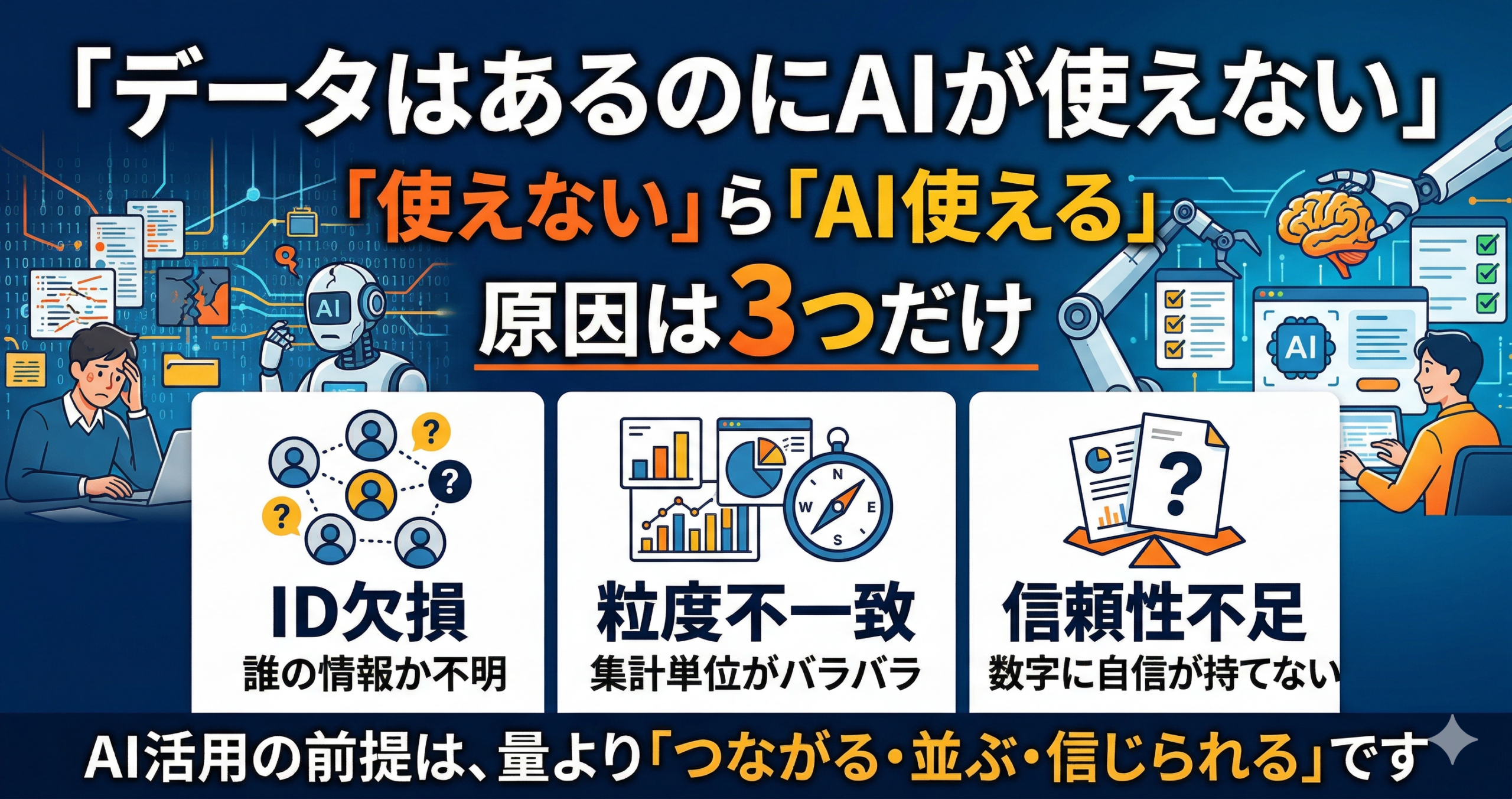
「データはあるのにAIが使えない」原因は3つだけ:ID欠損・粒度不一致・信頼性不足の棚卸しチェック
結論から言うと、データ基盤やツールを入れてもAI活用が進みにくいのは、モデルや機能の問題より前に、データの土台が「つながらない」「並ばない」「信じにくい」状態だからです。
現場で「結局使えない」と言われるとき、多くの場合は難しい話ではありません。誰のデータか分からない、同じ指標なのに集計単位が違う、見ている数字に自信が持てない。この三つが重なると、AIは動いても判断が止まりやすくなります。
この記事では、AI時代のデータ活用を止めやすい三つの原因を、概念→設計→運用→改善の順で整理します。棚卸しの型を持ち帰れるように、現場で使いやすい言葉に絞ってまとめます。
AI活用が止まる原因は、機能不足よりデータ土台の不整合にあることが多いです。
最初に見るべきは、ID欠損・粒度不一致・信頼性不足の三つです。
全部を高度化するより、棚卸しの型をそろえる方が前進しやすいです。
小さな対象範囲で詰まりを特定すると、改善の優先順位が見えやすくなります。


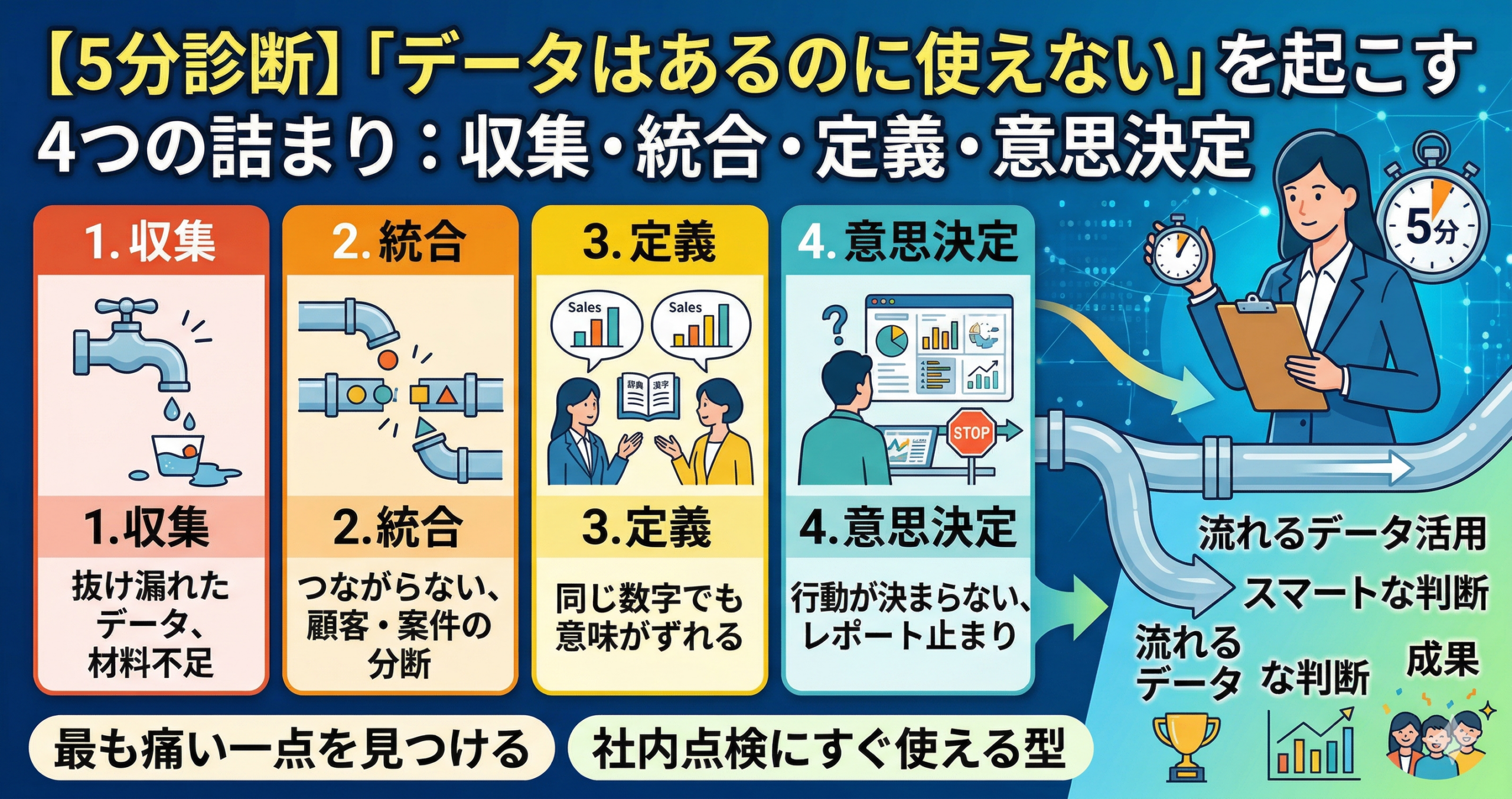
なぜ「データはあるのにAIが使えない」が起こるのか
結論として、AIはデータ量だけでは動ききれず、「誰の情報か」「同じ意味で比べられるか」「その数字を信じてよいか」がそろって初めて使いやすくなるためです。
AI活用の詰まりは、ツール導入の成否ではなく、入力されるデータの意味があいまいなことから起こりやすいです。つまり問題は「データがない」より、「AIに渡せる状態になっていない」に近いです。
たとえば、顧客データが複数システムに分かれ、同じ人物かどうかがつながらないと、AIは行動の流れを正しく読み取りにくくなります。また、広告は週次、営業は案件単位、CRMは配信単位のように粒度がずれると、同じ現象を横に並べても比較しにくくなります。
さらに、現場で「この数字は毎回ズレる」「定義が人によって違う」と感じている状態では、AIがどれだけきれいな出力を返しても、最終判断に使われにくくなります。つまり、AIが使えないのではなく、現場が安心して使える前提が整っていないのです。
ID欠損
同じ顧客や同じ案件を横断して追えず、点のデータのまま止まっている状態です。
粒度不一致
集計単位や更新タイミングがばらつき、比較や統合がしにくい状態です。
信頼性不足
定義や更新ルールが曖昧で、数字そのものに納得感が持ちにくい状態です。
- AI活用の前提は、量より「つながる・並ぶ・信じられる」です。
- 技術の問題に見えても、実際はデータ整理の問題であることがあります。
- 三つの詰まりを分けて見ると、改善の入口が見えやすくなります。
棚卸しチェックは、どんな型で見ると現場で使いやすいか
結論として、完璧なデータモデルを作る前に、「つながるか・並べられるか・信じられるか」の三段で棚卸しすると進めやすいです。
- 顧客や企業を横断して追えるIDがあるか
- チャネル別データが同じ対象へ結びつくか
- 重複や別名義の扱いが決まっているか
- 案件や商談まで流れを追えるか
- 日次・週次・月次の単位が混在しすぎていないか
- 媒体ごとの指標定義がそろっているか
- 同じ名前でも意味が違う項目がないか
- 比較したい粒度で集計し直せるか
- 誰が更新し、誰が確認するか明確か
- 欠損やズレが起きたときの扱いが決まっているか
- 現場が数字の意味を説明できるか
- 会議で毎回定義の説明から始まっていないか
- 全社横断より先に主要導線をひとつ選ぶ
- 完璧な統合を目指しすぎない
- 現場の違和感を材料にする
- “使う場面”から逆算して点検する
この型の利点は、専門用語が多くなりすぎないことです。たとえば「ID統合が未完了」と言うより、「同じ顧客を横断で追えない」と言った方が、現場では詰まりが伝わりやすいです。設計は難しく見せるより、誰でも異常に気づけることが重要です。
- 棚卸しは、技術要件より実務での使いにくさを起点にすると進めやすいです。
- つながる・並べられる・信じられるの三段で見ると整理しやすいです。
- 理想の設計図より、今の詰まりを言葉にできることが先です。
棚卸し結果を、日々の運用にどう落とし込むべきか
結論として、AI活用の前に「運用で迷う場所」を減らすと、現場での納得感が高まりやすいです。
棚卸しを一度して終わりにすると、数週間後には元の運用へ戻りやすいです。重要なのは、棚卸し結果をルールや確認ポイントとして現場へ落とすことです。
運用では、まずID欠損が起きやすい場面を明確にします。たとえば新規流入、名刺取り込み、問い合わせ入力など、入口で揺れやすい場所を押さえると、後工程のズレを減らしやすいです。
粒度不一致については、全部の数字を同じ単位に揃える必要はありません。むしろ、「この会議では週次、この判断では案件単位」というように、使う場面に応じて揃える基準を決める方が現実的です。
信頼性不足は、定義書を作るだけでは解消しにくいです。更新責任、確認タイミング、欠損時の扱いまで運用へ入れて初めて、数字に対する安心感が出やすくなります。
AI活用を前に進めるには、まず「現場がどこで立ち止まるか」を減らすことが有効です。迷いを減らした先に、AIの提案や要約が使われやすくなります。
- ID欠損は入口で起きやすい場所から見る
- 粒度は万能に揃えるより、使う場面で揃える
- 信頼性は定義だけでなく、更新と確認の運用まで含める
- 現場が止まるポイントを減らすことを優先する
どこから直すと、AI活用は前に進みやすいのか
結論として、最初は高度な分析基盤より、「最も痛みが大きい一点」を直す方が効果を感じやすいです。
改善でよくある迷いは、「全部壊れて見える」という状態です。ですが、実務では一度に全体を直す必要はありません。たとえば、顧客がつながらないのが一番つらいならID欠損から、会議で数字比較ができないなら粒度不一致から、現場が信用していないなら信頼性不足から着手する方が前に進みやすいです。
また、改善をAI導入プロジェクトだけの話にしないことも大切です。棚卸しで見つかった問題は、営業、CRM、広告、マーケOpsの運用改善にも直結しやすいため、日々の意思決定にどう効くかを基準に優先順位を置くと整理しやすいです。
ID欠損から直すべき場面
同じ顧客を追えず、施策や営業の履歴が分断されているときは、まず識別の整理が有効になりやすいです。
粒度不一致から直すべき場面
数字はあるのに比較できず、会議で毎回議論が空中戦になるときは、集計単位の整理が有効になりやすいです。
信頼性不足から直すべき場面
現場が数字を疑っていて、AIの提案も採用されにくいときは、定義と更新ルールの再確認が先になりやすいです。
- 改善は全体最適より、最も痛みが大きい一点から始める
- AI活用ではなく、日常判断がどう変わるかで優先順位を置く
- 改善後は、現場の使いやすさが増えたかを確認する
AIが使えないのではなく、使える前提が整っていないことが多い
結論として、AI活用を前進させるには、データ量を増やす前に「つながる・並べられる・信じられる」状態を棚卸しすることが必要です。
ID欠損は、同じ顧客や案件を流れとして追えなくする原因になりやすいです。
粒度不一致は、数字を持っていても比較しにくい状態を生みやすいです。
信頼性不足は、AI活用だけでなく現場判断そのものを止めやすいです。
次の一歩としては、まず主要な導線をひとつ選び、「誰のデータかは追えるか」「同じ単位で比べられるか」「現場が信じて使えるか」を棚卸ししてみるのがおすすめです。自社だけでは優先順位が見えにくい場合は、棚卸しの型を持って外部視点で確認すると、改善ロードマップを固めやすくなります。
何から始めればよいですか?
最初は一つの主要導線だけで十分です。たとえばリード獲得から商談化までの流れを対象に、三つの観点で棚卸しすると進めやすいです。
全部そろわないとAIは使えませんか?
その必要はありません。まずは一部の業務で、つながる・並べられる・信じられる状態を作る方が現実的です。
信頼性不足はどう見分ければよいですか?
会議で毎回定義確認が起きる、担当者ごとに数字の解釈が違う、現場が参考値としてしか見ていない、といった状態があるなら疑いやすいです。
棚卸しの後は何をすべきですか?
最も影響が大きい詰まりを一つ決め、運用ルールや確認方法まで含めて小さく直すのが進めやすいです。

「IMデジタルマーケティングニュース」編集者として、最新のトレンドやテクニックを分かりやすく解説しています。業界の変化に対応し、読者の成功をサポートする記事をお届けしています。