-7-320x180.png)



-2025-09-05T151236.591-320x180.png)









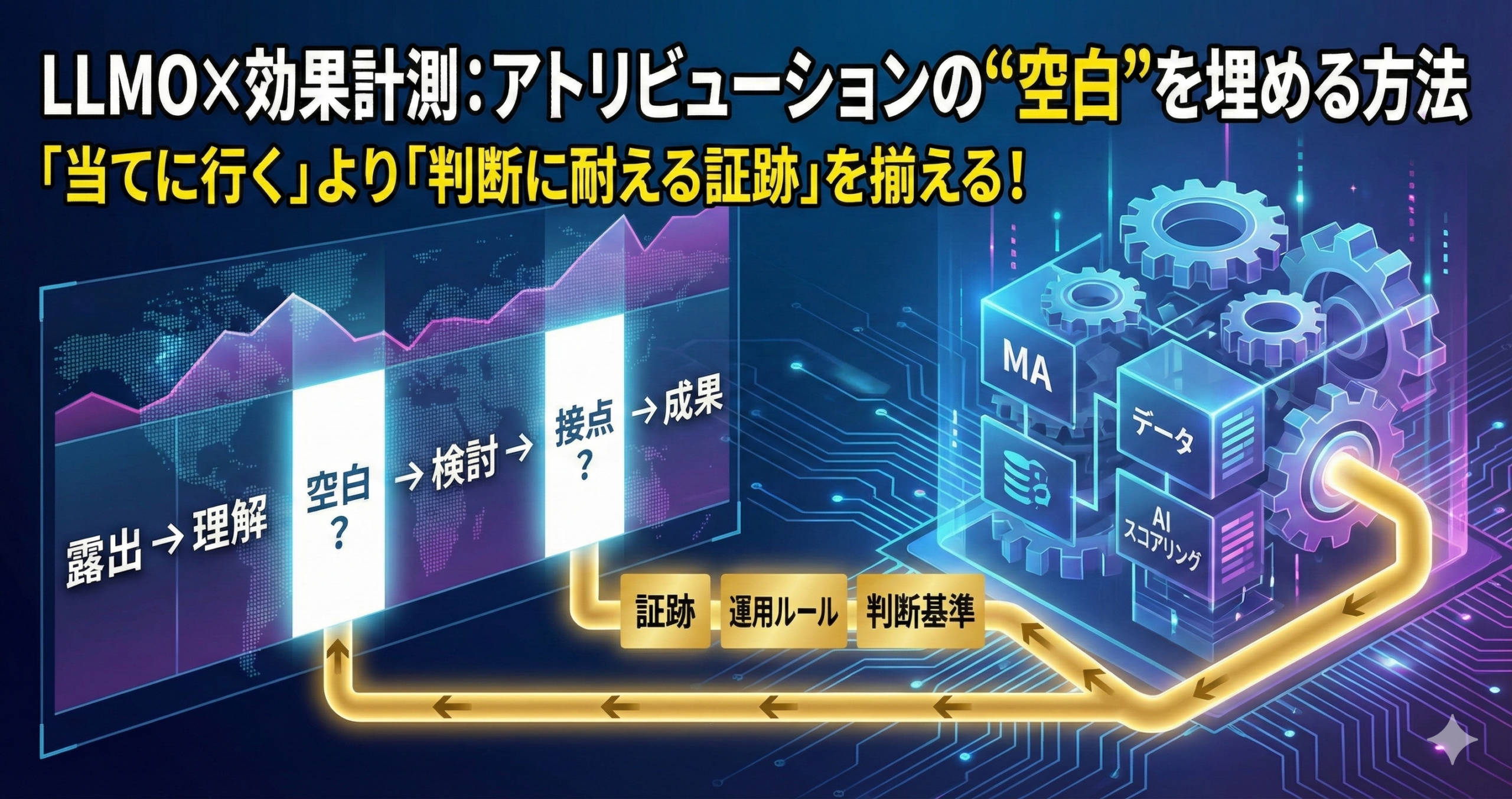
LLMO×効果計測:アトリビューションの“空白”を埋める方法
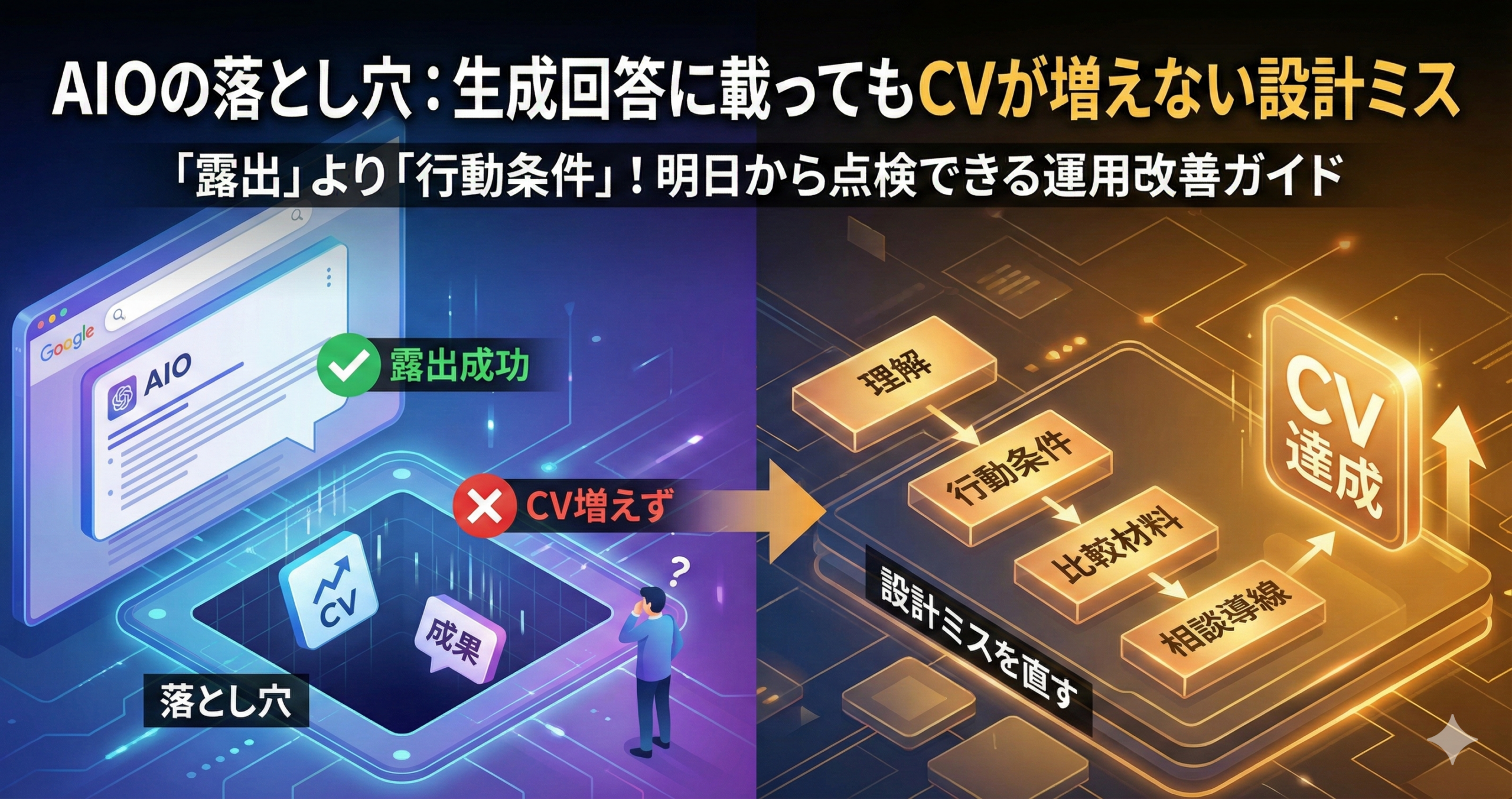
LLMO(生成AIに“拾われやすい情報設計”の最適化)が進むほど、コンテンツの影響は増えやすい一方で、効果計測では「何が効いたのか分からない」という状況も起きやすくなります。理由は、生成回答の中で理解が進み、クリックや直接の流入に表れない影響が増えるためです。
そこで必要になるのが、アトリビューションの“空白”をゼロにすることではなく、空白を前提に埋め方を標準化するという考え方です。本記事では、MA×データ×AIスコアリングを使って、効果計測のブレを抑え、現場で回せる形に落とし込みます。

-44-120x68.png)
イントロダクション
“リスト運用が感覚頼みになりやすい理由”と“MA×データ×スコアリングで何が変わるか”を提示します。
効果計測は、やろうと思えば無限に細かくできます。チャネル別、コンテンツ別、テーマ別、商材別、接点別など、切り口が増えるほど「見たい表」は増えます。
しかし、見たい表が増えるほど、現場では“計測リスト運用”が感覚頼みになりやすいです。たとえば、次のような状態が起きます。
指標やレポートが増える一方で、どれを意思決定に使うのかが曖昧になり、「良さそうな指標」や「見栄えの良い増減」に引っ張られます。LLMOは影響が間接化しやすいため、なおさら“見えるもの”に寄りがちです。
LLMOが関わる接点では、ユーザーが生成回答で理解を進め、その後に別の経路で指名検索・比較・相談へ進む、といった流れが起きやすいです。このとき、従来のアトリビューションだけだと、影響が空白になりやすくなります。
ここで役に立つのが、MA×データ×AIスコアリングです。MAは「どの状態の人に、どの案内を出したか」を運用で固定しやすく、計測の筋道を作れます。データは、単純な流入以外の証跡(問い合わせ理由、商談の論点、比較の動き、社内説明で詰まる点など)を集め、空白を埋める材料になります。AIスコアリングは、因果を断定するのではなく、“寄与の可能性”を判断する基準として使うと現場に落ちやすいです。
露出(参照される) → 理解(納得が進む) → 検討(比較が始まる) → 接点(相談に進む) → 成果(意思決定)
アトリビューションの空白は、上の流れの「露出」や「理解」に寄っている影響が見えにくいことから生まれます。見えにくいなら、見えやすい形に“運用で変換する”のが現実的です。
- 計測リストが増えるほど、指標運用は感覚頼みになりやすいです。
- LLMOは影響が間接化しやすく、アトリビューションに空白が生まれやすいです。
- MA×データ×AIスコアリングで、空白を前提に判断できる運用へ寄せやすくなります。
概要
用語整理と、掛け合わせたときに「運用」単位で何が変わるのかを整理します。
用語整理:MA / オルタナティブデータ / AIスコアリング
MA(マーケティングオートメーション)
配信の自動化というより、「状態に応じて案内を変える仕組み」です。効果計測では、案内のルールが揃っているほど、どの接点がどの役割を担ったかを説明しやすくなります。
オルタナティブデータ
クリックや流入以外の証跡です。問い合わせ理由、営業で出る反論、比較の論点、社内説明で詰まる点、導入後ギャップなど、LLMOの影響が出やすい“意思決定の摩擦”を示します。
AIスコアリング
正解を断定する道具ではなく、判断の軸を揃える道具です。アトリビューションの空白に対して「寄与の可能性」を同じ基準で扱えると、意思決定のぶれが抑えられます。
LLMO(生成AIに拾われる情報設計)
生成回答の中で参照されやすい構造・表現・根拠の置き方を整える考え方です。影響が「理解」や「検討」に出やすく、計測では“空白”が発生しやすい前提があります。
掛け合わせると、何が「運用」単位で変わるのか
この三つを掛け合わせると、効果計測は「チャネル別の集計」から「意思決定の筋道を説明する運用」へ寄っていきます。具体的には、次の単位で動かしやすくなります。
ターゲティング
誰の、どの迷いに答えるのかを、コンテンツと導線の役割で揃えます。曖昧だと、計測しても解釈がぶれやすいです。
優先順位
空白を埋めるために、どの証跡を先に揃えるかを決めます。やることを増やすより、基準を揃える方が進みやすいです。
ナーチャリング
生成回答で理解が進んだ人が、比較・相談へ進むための材料を、MAで状態別に渡せるようにします。
営業連携
商談の論点・反論・稟議の詰まりをデータとして回収し、コンテンツ改善と計測の双方に戻せるようにします。
空白をゼロにしようとすると、計測項目と運用負荷が膨らみやすいです。重要なのは、空白を前提に「説明に足る証跡」を揃え、改善が回る状態にすることです。
- MAは状態別の案内を固定し、計測の筋道を作りやすいです。
- オルタナティブデータは空白を埋める“証跡”として機能しやすいです。
- AIスコアリングは寄与の判断基準を揃える用途で使うと現実的です。
利点
“精度”ではなく“運用の再現性”に焦点を置き、改善されやすいポイントを整理します。
LLMO×効果計測の難しさは、「一つの指標で答えが出にくい」点にあります。だからこそ、精度を追いすぎず、再現性のある運用へ寄せることが有効になりやすいです。
属人化が抑えやすい
空白をどう扱うかをルール化すると、担当者ごとの解釈ブレが減りやすいです。「証跡の取り方」「報告の粒度」「例外の扱い」を揃えるのがポイントです。
優先順位のズレが減りやすい
流入指標だけで議論すると“見えるもの”に引っ張られがちです。意思決定の摩擦と証跡の不足から優先順位を決めると、改善の方向が揃いやすいです。
温度感の誤判定が減りやすい
生成回答経由のユーザーは理解が進んでいる場合があります。MAで状態別の案内を用意すると、過不足のあるコミュニケーションが起きにくくなります。
営業・CSと接続しやすい
商談の論点や反論は、空白を埋める強い証跡になりやすいです。現場の言語が入るほど、計測と改善が一体で回りやすくなります。
空白があること自体は問題になりにくいですが、意思決定の場で「なぜそう判断したのか」が説明できないと、改善の継続が止まりやすいです。だからこそ、空白の埋め方を“運用”として持つことが重要になります。
- 精度の追求より、判断の基準と証跡の取り方を揃える方が進みやすいです。
- 流入の増減だけでなく、意思決定の摩擦を起点に改善すると再現性が上がりやすいです。
- 現場の言語を計測に取り込むと、空白を説明しやすくなります。
応用方法
代表ユースケースと、どのデータをどう特徴量に落とすかを概念レベルで整理します。
代表ユースケース(BtoB中心)
LLMOの影響は「理解」や「比較」に出やすいため、効果計測も“検討の進み具合”を捉える設計が向いています。BtoBでは次のような運用が現実的です。
リード獲得後のスコアで配信シナリオを分岐
生成回答経由の人は前提理解が進んでいることがあります。用語説明よりも、比較軸・導入ステップ・稟議材料へ寄せるなど、状態に合わせた案内を用意すると、検討が進みやすくなります。
営業アプローチ順の最適化(判断基準として)
スコアを決め打ちにせず、優先順位の補助として使います。商談で必要な資料や説明順が揃うほど、空白の説明も取りやすくなります。
休眠掘り起こし(反応兆候の取り方)
生成回答で理解が進んだ人は、すぐに問い合わせないこともあります。比較の論点や反論に合わせて材料を送り直すと、再検討のきっかけになりやすいです。
空白を埋める“証跡”を標準化
クリックに寄せず、比較資料の閲覧、用語辞書の参照、相談前のチェックリスト利用など、検討の進み具合を示す証跡を揃えます。
BtoCへの読み替え(短く)
BtoCでは、比較と不安解消が中心になりやすいです。生成回答で要点が満たされるほど、残るのは「自分に合うか」「失敗しないか」「選び方は何か」といった判断材料です。効果計測も、購入直前だけを見るのではなく、判断材料に触れた証跡を整えると扱いやすいです。
どのデータを使い、どう特徴量に落とすか(概念)
特徴量という言葉は難しく聞こえますが、ここでは「後で同じ基準で振り返れる単位に整える」という意味です。LLMO×効果計測では、次の単位が扱いやすいです。
-
意図(何を知りたいか)
用語理解、比較、導入手順、稟議材料、相談前の不安解消など。生成回答の文脈と合わせて整理するとズレが減りやすいです。
-
摩擦(止まる理由)
判断軸がない、条件が分からない、リスクが不明、社内説明が難しい、相談の心理的ハードルが高い、など。空白を埋める優先度の基準になります。
-
証跡(検討が進んだサイン)
比較表の参照、チェックリストの利用、FAQの深掘り、導入手順の閲覧、相談ページの参照など。クリック以外の“行動の痕跡”として扱います。
-
言語(現場の言い回し)
問い合わせ文、営業の反論、商談メモ、サポート問い合わせなど。コンテンツの見出しや短い答えに落とすと、参照と計測の両方で揃いやすいです。
[画像案]「アトリビューションの空白マップ」
上段に「参照→理解→検討→接点→成果」の矢印。中段に“空白が出やすい領域”を斜線で表現。下段に「証跡(比較資料・チェックリスト・FAQ・相談導線)」のカードを並べ、空白に矢印でつなぐ。
- ユースケースは「検討が進む条件」を中心に設計すると、計測と改善がつながりやすいです。
- 意図・摩擦・証跡・言語に分けると、空白の説明がしやすくなります。
- BtoCでも、判断材料の証跡を揃える考え方は読み替えやすいです。
導入方法
導入を「設計→データ→モデル→運用→改善→ガバナンス」に分解し、チェックリスト形式で示します。
設計:目的とKPI(例:MQLの定義、優先度、営業SLA)
最初に決めたいのは、アトリビューションの空白を“何のために”埋めるのかです。目的が曖昧だと、証跡を増やしただけで疲弊しやすくなります。ここでは、LLMOの影響を「検討の前進」として扱い、意思決定に必要な説明ができる状態を狙うと整理しやすいです。
-
目的を二層で定義する
上位は「生成回答で理解した人を、比較・相談へ進める」。下位は「比較軸を提示」「稟議材料を渡す」「不安を減らす」など、運用に落ちる言葉にします。
-
MQLを“検討の証跡”で揃える
問い合わせだけに寄せず、比較や判断材料への接触を含めて定義します。定義が揃うほど、空白の議論が前に進みやすいです。
-
優先度の判断基準を置く
露出の増減より、摩擦の大きさと証跡の不足を優先する方針にすると、改善が迷走しにくいです。
-
営業SLAを“材料”で定義する
対応のタイミングだけでなく、相談時に揃える材料(課題整理、前提条件、比較軸)を含めます。接点の質が上がるほど、計測の説明も取りやすいです。
データ整備(名寄せ、欠損、更新頻度、粒度)
空白を埋めるには、クリック以外の証跡を揃える必要があります。ただし、すべてを取りに行くと運用負荷が上がりやすいです。まずは、意思決定の筋道に必要な証跡を、少ない種類で安定運用することを優先すると現場に落ちます。
同じ内容でも言い方が揺れると、コンテンツも計測も分断されやすいです。「比較」「選定」「検討」「稟議」「相談」など、よく使う言葉の意味と範囲を社内で揃えると、空白を説明しやすくなります。
-
データの粒度を決める
ページ単位、テーマ単位、導線単位など、分析の単位を揃えます。単位が揺れると、議論が散らばりやすいです。
-
欠損を前提に扱う
全部が揃わない前提で、空白が残る箇所は「補助証跡で埋める」方針にします。
-
更新頻度をルール化する
毎回の全面改修は避け、見直す範囲(辞書・FAQ・比較材料・導線)を決めます。
-
問い合わせ理由を回収する
問い合わせフォームやヒアリングで「何を見て」「何が分からず」「何を判断したいか」を短文で取れる形にします。
-
商談の反論と言語を回収する
繰り返し出る反論は、空白を埋める強い証跡です。見出し・FAQ・比較軸に戻せる形にします。
-
検討の証跡を定義する
比較表、チェックリスト、導入手順など、検討が進む材料への接触を“証跡”として扱います。
スコアの使い方(しきい値、分岐、例外処理)
AIスコアリングは、寄与を断定するためではなく、空白のある状況でも同じ基準で判断できるようにするために使います。ポイントは、スコアに過剰に依存せず、理由が残る運用にすることです。
摩擦(止まる理由) → 証跡(進んだサイン) → 材料(不足しているもの) → 判断(優先順位)
-
しきい値は固定しすぎない
状況により“重視する証跡”が変わることがあります。運用で調整できる余地を残します。
-
分岐は少数から始める
比較が必要、条件整理が必要、不安解消が必要、など大枠で分けます。増やす条件を決めておくと拡張しやすいです。
-
例外処理を先に用意する
断定が難しいテーマは、判断の軸と確認事項を提示する設計にします。過度な一般化を避けられます。
-
理由を短文で残す
「どの摩擦に対し、どの証跡が不足し、何を足すか」を簡潔に残すと、ブラックボックス化が起きにくいです。
現場オペレーション(運用担当・営業・CSの役割)
LLMOの影響を計測に落とすには、編集・運用だけで完結しにくいです。空白を埋める証跡は、営業やCSが持っていることが多いからです。役割分担を決め、言語を往復させると、計測が“説明できる形”になりやすいです。
-
運用担当:計測ルールとログの管理
証跡の定義、更新タイミング、例外の扱いを運用として整えます。
-
編集:短い答えと比較材料の整備
生成回答で拾われやすい要点を押さえつつ、検討が進む材料へ自然に接続します。
-
営業:反論・論点・稟議の詰まりを入力
商談で繰り返し出る質問を“言語データ”として回収し、コンテンツと計測に戻します。
-
CS:導入後ギャップと注意点を入力
導入後に出るズレは、空白を埋める重要な手掛かりです。注意点や例外として反映します。
品質管理(ドリフト、誤判定、再学習の考え方)
LLMO×効果計測は、環境の変化で効き方が揺れやすいです。ここでの品質管理は「当たり外れ」を追うより、ズレの種類を分類して、直し方を揃えることが要点になります。
参照は増えたが相談が増えない、比較材料は見られるが前に進まない、FAQは増えたが不安が残る、など。ズレの種類が分かれば、証跡の取り方を変えるのか、材料を足すのか、導線を整えるのかが決めやすいです。
-
ズレのログを残す
ズレの種類と、直した内容を短文で残します。説明責任が取りやすくなります。
-
誤判定は“条件不足”として扱う
断定できない場合は、前提条件や確認事項を追記し、過度な一般化を避けます。
-
再学習は“評価軸”の見直しから
摩擦・証跡・材料のどれがズレたかを先に確認し、施策の積み増しだけで解決しないようにします。
-
運用負荷の上限を決める
追う証跡の種類を絞り、改善が回る範囲を維持します。広げるのは回ってからにします。
リスクと注意点(ブラックボックス化、運用負荷、過学習“っぽい”兆候)
空白がある状況でAIを使うと、「AIがそう言っているから」という説明になりがちです。これがブラックボックス化の入口になります。スコアや分類は、必ず“理由の言語化”とセットにし、判断の軸を残すことが大切です。また、空白を埋めようとして証跡を増やしすぎると、更新が追いつかず品質が落ちるリスクがあります。
- AIは断定の道具ではなく、判断基準を揃える補助として使うと安全です。
- 証跡を増やしすぎると運用負荷が上がるため、最小構成から始めるのが現実的です。
- 説明不能になりそうな時は、評価軸(摩擦・証跡・材料)に立ち返ると整理しやすいです。
未来展望
“AIスコアリングが一般化すると何が標準化されるか”を運用/組織/データ観点で整理します。未来は断定せず可能性として述べます。
LLMOが広がるほど、効果計測は「クリック中心」から「意思決定の筋道中心」へ寄っていく可能性があります。生成回答が要点を示す場面では、コンテンツは“全文を読む場所”というより、比較や相談の判断材料を揃える場所としての役割が強まるかもしれません。
運用で標準化されやすいこと
証跡の定義、改善ログの書き方、例外処理のルール、状態別シナリオの型。空白を扱う“運用の型”が整う可能性があります。
組織で標準化されやすいこと
編集・営業・CSの言語往復、反論の収集、稟議の詰まりの共有。効果計測が“現場の言語”と結びつきやすくなる可能性があります。
データで標準化されやすいこと
意図・摩擦・証跡・言語の整理。コンテンツ設計と計測が同じ辞書で語られるようになる可能性があります。
差が残りやすいこと
例外処理の丁寧さ、証跡の最小構成を守る姿勢、改善の継続力。運用品質が差になりやすい領域です。
空白を完全に消す方向ではなく、空白を前提に「説明できる証跡」を揃える方向へ、現場の設計が進むかもしれません。結果として、効果計測は“ひとつの指標の勝負”ではなく、運用ルールとログの質で差が出る可能性があります。
- 効果計測は、意思決定の筋道を説明する方向へ寄る可能性があります。
- 標準化は、辞書・証跡・ログなど運用の部品から進みやすいです。
- 差は、例外処理と継続運用の品質に残りやすい可能性があります。
まとめ
要点を簡潔に再整理し、次アクションを「小さく始める」方針で提示します。
LLMOが効くほど、アトリビューションには空白が生まれやすくなります。ここで大切なのは、空白をゼロにすることではなく、空白があっても判断できる運用へ寄せることです。MAで案内の筋道を揃え、オルタナティブデータで証跡を補い、AIスコアリングで判断の基準を揃えると、改善が続きやすくなります。
小さく対象導線を絞る → 揃える辞書と言語 → 定める証跡の最小構成 → 回すMAで状態別案内 → 残すログで説明
- 空白は“悪”ではなく、前提として扱うと運用が進みやすいです。
- クリック以外の証跡(比較・判断材料への接触)を最小構成で揃えるのが現実的です。
- AIスコアリングは断定ではなく、判断基準を揃える用途で使うと安全です。
- 次アクションは、対象を絞って辞書・証跡・ログの型を作るところから始めると回しやすいです。
FAQ
初心者がつまずきやすい点を中心に、断定せず判断の軸と確認事項を提示します。
LLMOの効果は、通常の流入指標だけで追えますか?
追える部分はありますが、空白が出る可能性があります。生成回答で理解が進むと、別の経路で比較・相談に進むことがあるためです。流入指標に加えて、比較材料への接触や相談前の行動など、検討の証跡を合わせて見ると判断しやすくなります。
- 生成回答で扱われやすいテーマを把握できているか
- 比較や判断材料への接触が計測できているか
- 問い合わせ理由の回収ができているか
アトリビューションの“空白”は、どういうときに生まれやすいですか?
露出や理解が先に進み、クリックや直接の流入に残りにくいときに生まれやすいです。特に、用語理解・比較軸・注意点など「読む前に要点が分かる」領域では、間接効果が増えることがあります。空白を前提に、証跡の最小構成を決めておくと運用が安定しやすいです。
- 露出と成果を同一視していないか
- 比較と相談の材料が揃っているか
- 空白を埋める証跡が決まっているか
何から始めると失敗しにくいですか?
対象を絞って、辞書と言語を揃えるところから始めると進みやすいです。計測の項目を増やす前に、意図・摩擦・証跡の定義を揃えると、後から拡張しても迷走しにくくなります。
- 対象導線(相談までの流れ)を絞れているか
- 用語の定義と範囲が揃っているか
- 最小構成の証跡が合意できているか
どんなデータを集めると、空白を説明しやすくなりますか?
クリック以外の証跡と、現場の言語が有効になりやすいです。比較材料の参照、チェックリストの利用、FAQの深掘りなどの行動と、問い合わせ理由・商談の反論・稟議の詰まりといった言語データを揃えると、意思決定の筋道を説明しやすくなります。
- 比較や判断材料への接触が取れているか
- 問い合わせ理由を短文で回収できているか
- 商談の反論が整理されているか
AIスコアリングを使うと、説明が難しくなりませんか?
説明が難しくなるのは、理由が残らないときです。スコアは決め打ちにせず、摩擦・証跡・材料のどれが不足しているかを短文で残す運用にすると、ブラックボックス化が起きにくくなります。
- 評価軸(摩擦・証跡・材料)が言語化されているか
- 例外処理(手動判断)のルールがあるか
- 採用理由と変更理由がログに残るか
MAがなくても、空白を埋める運用はできますか?
できます。MAは状態別の案内を標準化しやすいですが、先に効くのは「辞書と言語」「証跡の定義」「ログの運用」です。手運用で回り始めたら、繰り返し作業から自動化を広げる形でも進めやすいです。
- 案内の役割分担(理解・比較・相談)が決まっているか
- 証跡が最小構成で揃っているか
- ログが継続して残る仕組みがあるか
運用が重くなりそうで不安です。どう抑えれば良いですか?
証跡の種類を絞り、更新の範囲を決めると抑えやすいです。空白を埋めるために何でも追うと、更新が追いつかず品質が落ちることがあります。最小構成の証跡と、見直す範囲(辞書・FAQ・比較材料・導線)を先に決めるのが現実的です。
- 証跡の種類が増えすぎていないか
- 更新頻度と更新範囲が決まっているか
- 例外処理の方針があるか
- 空白はゼロにするより、説明に耐える証跡を揃える方向が現実的です。
- 辞書・証跡・ログの型ができると、担当者が変わっても運用が続きやすいです。
- AIは断定ではなく、判断基準を揃える補助として使うと安全です。
免責:本記事は一般的な考え方の整理です。業種・商材・導線・組織体制により最適な計測設計は変わり得るため、現場の状況に合わせて調整してください。

「IMデジタルマーケティングニュース」編集者として、最新のトレンドやテクニックを分かりやすく解説しています。業界の変化に対応し、読者の成功をサポートする記事をお届けしています。