-7-320x180.png)



-2025-09-05T151236.591-320x180.png)








LLMO×トラッキング:AI検索経由の成果をどう計測する?設計ガイド
AI検索(回答型の検索や要約)を起点に、ユーザーが「読む→比較する→社内で共有する→問い合わせる」まで進む流れは、従来の検索よりも経路が複線化しやすいです。
その結果、成果が出ていても“見えない”、あるいは見えている数値が“誤解”を招くことがあります。
本記事では、LLMOの成果を追うために、何を「成果」と定義し、どこでログを取り、どう合意するかを、設計→運用→改善までの手順として整理します。
💬 先に要点:AI検索は「流入」より「引用・再訪・共有」を拾うと実態に近づきやすいです
AI検索経由の成果は、クリックの一発で完結しないことがあります。
そのため、入口(AI検索)の識別だけでなく、中間行動(読む・比較・保存・共有)を設計し、営業接続(問い合わせ・資料請求)までの“説明可能なストーリー”を作るのが現実的です。


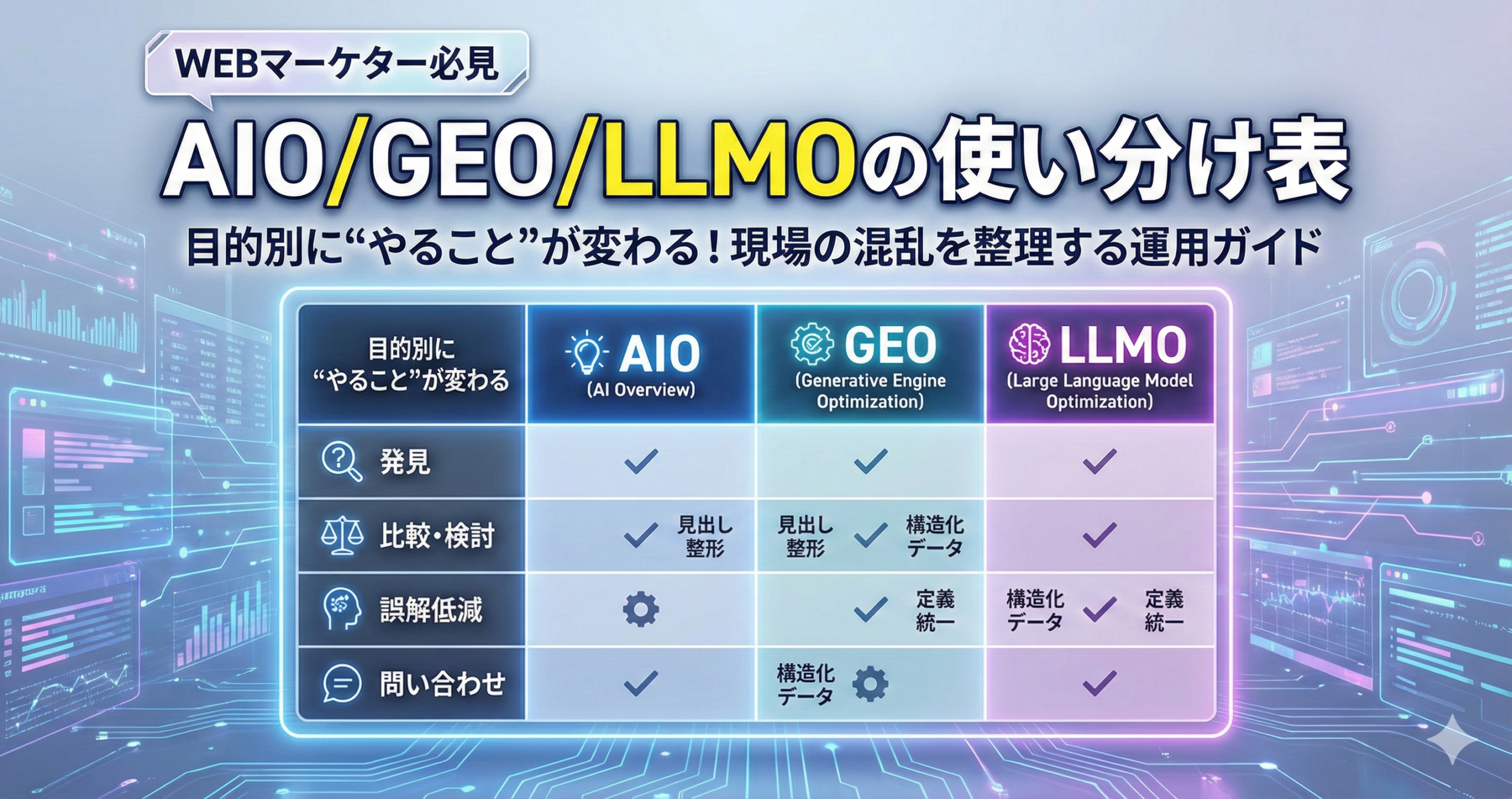
イントロダクション
“リスト運用が感覚頼みになりやすい理由”と“MA×データ×スコアリングで何が変わるか”を提示します。トラッキングは「作って終わり」ではなく、棚卸しの運用が必要になりやすい領域です。
AI検索の計測が難しく感じる背景には、経路が増えるのに、見えるシグナルが減るというギャップがあります。
たとえば、AIの回答内で情報を理解し、後で指名検索やブックマークから再訪する。社内チャットで共有され、別の人が問い合わせる。こうした動きは現場感としては増えますが、単純な流入レポートでは取りこぼしやすいです。
ここで「リスト運用が感覚頼みになりやすい」とは、AI検索の計測で増えがちな次のリストを指します。
参照元の分類リスト、パラメータ命名リスト、イベント定義リスト、例外処理リスト。
これらが担当者の経験で増えていくと、継ぎ足しで整合が崩れ、説明が難しくなりがちです。
🧩 感覚頼みになりやすい理由
- AI検索の参照元は、常に同じ形で渡ってこないことがある
- クリックがない“影響”が存在し、単純な流入で見えにくい
- 再訪・共有・指名検索など、寄与の経路が複線化しやすい
- 例外が増え、命名・分類が属人化しやすい
- レポートが増えるほど、結論がぶれやすい
🛠️ MA×データ×スコアリングで何が変わるか
AI検索経由の成果を「説明可能」にするには、運用の型が必要になりやすいです。
MA×データ×スコアリングを補助輪として使うと、計測が“現場で回る”形に寄せやすくなります。
- MA:イベントの実装だけでなく、レポート配信・アラート・棚卸しを定期運用にする
- データ:AI検索由来の行動を、再訪・共有・問い合わせの文脈でつなぐ
- スコアリング:計測の信頼度(曖昧/確からしい)を扱い、点検の順番を作る
- AI検索経由の成果は、クリックだけで完結しないことがあります
- リスト(命名・分類・例外)が増えるため、最初にルールを作ると属人化を抑えやすいです
- MA×データ×スコアリングは、計測を“説明可能”にする運用の補助輪になります
概要
用語整理:MA / オルタナティブデータ / AIスコアリング。あわせて、AI検索経由の計測で起きやすいズレを整理し、「運用」単位で変わる点(ターゲティング、優先順位、ナーチャリング、営業連携)を具体化します。
まず押さえる:AI検索経由の「成果」は複数レイヤーに分かれやすい
AI検索の計測は、「流入」「行動」「成果」を同列に扱うと誤解が起きやすいです。
そこで、成果を次のレイヤーに分けて定義すると、レポートが読みやすくなります。
🧾 用語整理:MA / オルタナティブデータ / AIスコアリング
ここでは、計測設計の文脈で用語を噛み砕いて整理します。
- MA:ナーチャリングや配信の仕組みだけでなく、計測イベントを活用した“運用(配信・通知・棚卸し)”の仕組み
- オルタナティブデータ:流入以外のシグナル(社内共有の文脈、問い合わせ要旨、比較軸、誤解ポイントなど)を補う材料
- AIスコアリング:成果を断定するためではなく、計測の確からしさ・点検優先度を扱う仕組み
三つを掛け合わせると、運用単位で何が変わるのか
AI検索経由の計測を、単なる実装作業ではなく運用として回すと、次の領域が整いやすくなります。
「AI検索→サイト→再訪→共有→問い合わせの行動フロー図」
「計測レイヤー(入口・中間・成果)マップ」
「命名規則テンプレ(source / medium / campaign / content / term の役割)」
「イベント設計カタログ(閲覧深度・比較・保存・共有・問い合わせ)」
「計測の信頼度ラベル(確からしい/曖昧/要点検)」
- AI検索の成果は「入口・中間・成果」に分けると、レポートの誤解が減りやすいです
- MA・オルタナティブデータ・スコアリングを組み合わせると、計測が運用として回りやすいです
- 運用単位で整理すると、コンテンツ改善と営業接続を同じ物差しで語りやすくなります
利点
よくある課題→改善されやすいポイントを整理し、“精度”ではなく“運用の再現性”に焦点を置きます。AI検索は計測が揺れやすいので、説明のしやすさを重視します。
AI検索の計測で得られる利点は、単に「新しい流入源が見える」ことだけではありません。
どの説明が、どの段階の意思決定に効いたのかを、社内で共有できる形にしやすい点にあります。
🧩 よくある課題
- AI検索の寄与が見えず、施策が過小評価されやすい
- 参照元の分類が揺れ、レポートの数字が信用されにくい
- イベントが増えすぎて、何を見れば良いか分からない
- 中間行動が取れておらず、成果までのストーリーが語れない
- 例外処理が属人化し、引き継ぎが難しくなる
🛠️ 改善されやすいポイント(再現性)
- 入口の識別を“可能な範囲”で揃え、曖昧さをラベルで扱える
- 中間行動を標準化し、過小評価や誤判定を減らしやすい
- 命名規則が揃い、レポートの読み手が迷いにくい
- 営業・CSに引き渡せる“行動ストーリー”が作りやすい
- 棚卸し運用で、例外が増えすぎるのを抑えやすい
⚠️ 誤判定が起きやすいポイント(人間の直感が外れやすい)
AI検索は、ユーザーが「クリックしないで理解する」ケースが増えると、従来の直感が外れやすいです。
たとえば、流入が少ないのに問い合わせが増える、あるいは流入が増えたのに商談につながらない、といったズレが起きえます。
ここで重要なのは、数字を断定材料にするのではなく、どのレイヤー(入口・中間・成果)が変わったのかを分けて観察することです。
- 入口が増えても中間行動が弱い場合は、説明の部品(定義・比較・注意点)が不足している可能性があります
- 入口が見えなくても成果が出る場合は、再訪・共有・指名検索の寄与が疑えます
- 成果だけを見ると、原因が見えにくいので、中間行動をセットで拾うと説明しやすいです
- AI検索の計測は、曖昧さを“扱える形”にすると現場で回りやすいです
- 中間行動を標準化すると、成果までのストーリーが語りやすくなります
- 棚卸し運用があると、例外の増殖や属人化を抑えやすいです
応用方法
代表ユースケースを提示します。BtoBを軸に、BtoCの読み替えも示します。“どのデータを使い、どう特徴量に落とすか”を概念レベルで解説します。
リード獲得後のスコアで配信シナリオを分岐(AI検索経由の理解段階に合わせる)
AI検索経由のユーザーは、初回訪問時点で理解が進んでいる場合もあれば、逆に誤解が含まれている場合もあります。
そのため、ナーチャリングでは「同じ資料を一斉に送る」より、理解段階の違いに合わせて情報部品を出し分けると運用が安定しやすいです。
🧩 分岐に使える中間行動(例)
- 定義のページを見た:基礎理解の段階
- 比較表を見た:選定の段階
- 注意点・リスクを見た:稟議・合意の段階
- 事例・手順を見た:導入検討の段階
- FAQを見た:不安解消の段階
🛠️ トラッキングの設計ポイント
- 中間行動は、増やしすぎず“段階を識別できる最小限”に絞る
- イベント名は、意味が伝わる命名にして引き継ぎ可能にする
- 曖昧な流入は、無理に断定せず「AI由来の可能性」として扱う
- AI検索経由は理解段階が揺れやすいので、中間行動で段階を推定すると運用しやすいです
- イベントは最小限に絞り、命名で意味を残すと引き継ぎが楽になります
- 曖昧な流入は、ラベルで扱うと誤判定を抑えやすいです
営業アプローチ順の最適化(判断基準としての“行動ストーリー”)
AI検索経由のリードは、どの情報を読んで、どんな不安を解消しているかが見えると、営業の優先度づけがしやすくなります。
ただし、ここでも断定は避け、判断基準として扱うのが安全です。
| 営業に渡すと効きやすい情報 | 「どの比較軸を見たか」「注意点を見たか」「FAQのどの種類に反応したか」など、会話の糸口になる情報が役立ちやすいです。 |
|---|---|
| 誤判定を減らす扱い | 行動ログは“確定情報”ではなく、仮説として扱います。 たとえば「比較表を見た=検討が進んでいる」と断定せず、「比較を始めた可能性」として会話で確認します。 |
| BtoCの読み替え | 営業アプローチを、サポートの優先対応や、レコメンドの優先度に置き換えます。 中間行動のログは、説明の出し分けに使いやすいです。 |
- 営業連携では、行動ログを“仮説の材料”として渡すと安全です
- 会話で確かめる前提で運用すると、誤判定のリスクが下がりやすいです
- BtoCは、サポートやレコメンドに読み替えると実務に馴染みやすいです
休眠掘り起こし(反応兆候の取り方:再訪・共有を拾う)
AI検索経由の寄与は、初回流入だけでは見えにくいことがあります。
休眠掘り起こしでは、再訪や共有といったシグナルが役立ちやすいです。
たとえば、社内共有で別担当が再訪する、あるいは後日指名で戻る、といった動きがありえます。
🧠 反応兆候の例(概念)
- 短期の再訪:同じテーマを複数回読む(比較を始めた可能性)
- 共有の兆候:コピー、共有ボタン、同一URLの複数アクセス(組織内共有の可能性)
- 深掘り行動:比較表→注意点→FAQの順に読む(合意形成の準備の可能性)
- ナーチャリング反応:メール経由で再訪し、同テーマを再読する(検討が進んだ可能性)
- 休眠掘り起こしは、再訪・共有などの中間行動が手がかりになりやすいです
- AI検索経由の寄与は、初回流入に出ない形で現れることがあります
- 兆候は断定せず、運用の判断基準として扱うと誤解が減りやすいです
どのデータを使い、どう特徴量に落とすか(概念レベル)
特徴量という言葉は難しく聞こえますが、ここでは「判断材料として扱える形」に整える、という意味で使います。
AI検索の計測では、入口の識別が不確かなことがあるため、入口だけに頼らず、中間行動と運用データで補うと説明しやすいです。
- 入口の識別が曖昧でも、中間行動と文脈データで説明を補えます
- 確からしさのラベルを作ると、断定による誤判定を抑えやすいです
- 特徴量は「判断材料として扱える形」にする、という理解で十分です
導入方法
導入を「設計→データ→モデル→運用→改善→ガバナンス」で分解し、チェックリスト形式で示します。AI検索経由の成果を“説明可能”にするための最小構成を作ります。
「計測設計の全体像(目的→KPI→イベント→命名→棚卸し)」
「参照元の分類ルール(確からしい/曖昧/不明)」
「イベント命名のルール(カテゴリ_動詞_対象)」
「改善ループ(例外検知→原因→修正→合意→展開)」
「営業・CS連携の引き渡しカード(行動ストーリー)」
設計(目的/KPI:MQLの定義、優先度、営業SLA)
AI検索の計測は、目的が曖昧だと「イベントが増えるだけ」になりやすいです。
まずは、目的を“評価軸”で言い換え、KPIを運用に落とせる形にします。
BtoBでは、MQLの定義や営業SLAと接続し、どの段階の行動を拾うと営業が動きやすいかを合意します。
- 目的を評価軸で定義すると、イベントが増えすぎるのを抑えやすいです
- 成果はレイヤーで分けると、説明と合意が取りやすいです
- 確からしさラベルは、断定による誤判定を抑える安全弁になります
データ整備(名寄せ、欠損、更新頻度、粒度)
AI検索の参照元は、常に同じ情報が渡ってくるとは限らないため、欠損や例外を前提に設計する方が現実的です。
ここでは「名寄せ=同じ意味のものをまとめる」「粒度=判断できる単位に揃える」という考え方で整理します。
🏷️ 名寄せ(参照元・キャンペーンの名寄せ)
- 参照元の表記ゆれをまとめる(同じ意味を同じラベルへ)
- AI検索由来の分類を“確からしさ”で段階化する
- キャンペーン名は、目的と期間が読み取れる形に揃える
🧩 欠損・更新頻度・粒度
- 欠損は“ゼロ埋め”より、欠損として扱い、原因を棚卸しで潰す
- 更新頻度は、変更が多い箇所(命名・分類・例外)を優先して点検する
- 粒度は、運用で判断できる単位に揃える(ページ種別・イベントカテゴリなど)
🧾 命名の基本方針(おすすめの考え方)
命名は、ツールの都合よりも「人が読んで意味が分かる」ことを優先すると運用が続きやすいです。
たとえば、カテゴリ_動詞_対象のように、意味が伝わる形に揃えると引き継ぎで迷いにくくなります。
- カテゴリ:acq(獲得)/ engage(閲覧・比較)/ lead(問い合わせ)など
- 動詞:view / compare / save / share / submit など(日本語の運用でも可)
- 対象:definition / table / faq / form など
- 参照元の名寄せと確からしさラベルは、レポートの信用を上げやすいです
- 欠損は隠さず、原因を棚卸しで潰す運用が現実的です
- 命名は“人が読める”ことを優先すると継続しやすいです
モデル(スコアの使い方:しきい値、分岐、例外処理)
ここでの「モデル」は、機械学習モデルに限りません。
実務では、ルールベースのスコアで十分なこともあります。
目的は「AI検索由来の寄与」を断定することではなく、点検の順番と、運用の分岐を作ることです。
⚠️ 例外処理が増えすぎるサイン
- 同じ参照元を、担当者ごとに違う分類で扱っている
- 命名ルールが崩れ、意味が追えない値が増えている
- 欠損が増えているのに、原因の棚卸しが止まっている
- レポートの数字に、関係者が納得できなくなっている
- モデルは高度でなくても、確からしさの段階化で運用が回りやすいです
- しきい値は“運用判断”に使える形に寄せると現場に馴染みます
- 例外処理はテンプレ化し、棚卸しで増殖を抑えると安全です
現場オペレーション(運用担当・営業・CSの役割)
AI検索の計測は、実装担当だけでは回りにくいことがあります。
とくに「何が成果に寄与したのか」は、営業・CSの現場感と結びつけると説明しやすいです。
👥 役割分担テンプレ(計測運用)
- 計測運用(マーケ):定義・命名・分類ルールの管理、例外の棚卸し、レポート整備
- コンテンツ運用:中間行動の設計(ページ種別・CTA)、改善施策の実装
- 営業:問い合わせ要旨の共有、比較軸の妥当性、引き渡し条件の合意
- CS:誤解されやすい点、注意点の把握、FAQ改善の材料提供
- 管理者:例外の増殖抑制、棚卸し会の開催、運用ルールの維持
- 計測の運用は、棚卸し会など“場”を作ると継続しやすいです
- 営業・CSの現場感を取り込むと、寄与の説明が具体化しやすいです
- 管理者は例外の増殖を抑える役割を持つと運用が安定しやすいです
品質管理(ドリフト、誤判定、再学習の考え方)
AI検索の計測は、参照元の変化や仕様変更などで、分類が徐々に崩れることがあります。
そのため、ドリフト(ズレ)を前提に、兆候を早めに拾う運用が現実的です。
🧭 ドリフトの兆候(点検の合図)
- 「不明」や「その他」の割合が増える
- 同じ参照元が別ラベルに割れている
- イベントの欠損が増える(実装漏れ・仕様変更の可能性)
- レポートの読み手が、数字に納得しなくなる
- ドリフトは前提として、兆候を拾う仕組みを作ると運用が安定しやすいです
- 再学習は大きな話にせず、分類ルールの更新で十分な場合があります
- 「不明の増加」は、棚卸しのトリガーとして扱いやすいです
リスクと注意点(ブラックボックス化、運用負荷、過学習“っぽい”兆候)
計測は、増やせば増やすほど良いわけではありません。
イベントや命名が増えすぎると、レポートが読めなくなり、ブラックボックス化しやすいです。
また、特定の参照元だけを過剰に追いかけると、運用判断が偏ることがあります。
⚠️ 代表的なリスクと回避の方向性
- ブラックボックス化:命名規則・分類ルール・理由ログを残し、説明可能性を保つ
- 運用負荷:イベントを最小構成に絞り、増やす前に棚卸しで必要性を確認する
- 過学習っぽい兆候:特定の参照元に寄りすぎたら、成果レイヤーで再整理する
- 誤判定:確からしさラベルで扱い、断定を避ける
- 更新漏れ:棚卸しの頻度と担当を決め、例外の増殖を抑える
- 計測は最小構成から始め、棚卸しで育てると運用負荷を抑えやすいです
- 説明可能性(命名・分類・理由ログ)がないと、ブラックボックス化しやすいです
- 確からしさラベルは、断定による誤判定を抑える実務的な手段です
未来展望
“AIスコアリングが一般化すると何が標準化されるか”を、運用/組織/データ観点で整理します。未来は断定せず、可能性として述べます。
AI検索の利用が広がるほど、成果の説明は「流入」だけでなく「理解・共有・再訪」を含むストーリーで語られる方向に進む可能性があります。
その場合、計測は単なるツール設定ではなく、合意形成のインフラとして扱われる場面が増えるかもしれません。
🧩 運用で標準化されやすいこと
- 成果レイヤー(入口・中間・成果)でのレポート設計
- 確からしさラベルの運用(曖昧さを扱う)
- イベントの最小構成と、増やす基準
- 棚卸し会の定期運用(例外の増殖を抑える)
🏢 組織で標準化されやすいこと
- 営業・CSと共有できる“行動ストーリー”の引き渡し
- 命名規則と分類ルールのガイドライン
- 断定表現を避けるデータ運用(推定は推定として扱う)
- 問い合わせ要旨の構造化(オルタナティブデータの整備)
🗂️ データで標準化されやすいこと
- 参照元の名寄せ辞書(表記ゆれを吸収する)
- 例外処理テンプレ(未知・欠損・新規参照元の扱い)
- 品質点検の指標(不明の増加、欠損の増加など)
- AI検索の計測は、曖昧さを扱う標準が整う可能性があります
- レポートは流入だけでなく、理解・共有・再訪を含む形に寄るかもしれません
- 棚卸し運用は、例外の増殖を抑える中核になりやすいです
まとめ
本記事の要点を再整理し、次アクションを「小さく始める」方針で提示します(PoC→運用適用の流れ)。
LLMO×トラッキングでは、AI検索の寄与を“完全に”特定するより、説明可能な形で拾い、改善につなげることが重要になりやすいです。
入口の識別が曖昧でも、中間行動やオルタナティブデータで補うと、意思決定に使える形にできます。
そして、計測は棚卸しを前提にしないと、例外と命名が増えて破綻しやすいです。
✅ 要点
- 成果は「入口・中間・成果」のレイヤーで分けると誤解が減りやすいです
- AI検索由来は断定せず、確からしさラベルで扱うと運用が安定しやすいです
- 中間行動(比較・注意点・FAQなど)を拾うと、寄与のストーリーが語りやすいです
- 命名規則と名寄せ辞書がないと、レポートの信用が落ちやすいです
- 棚卸し運用があると、例外の増殖と属人化を抑えやすいです
次アクション(小さく始める:PoC→運用適用)
- 最小構成で始め、棚卸しで育てると運用負荷を抑えやすいです
- 確からしさラベルは、断定による誤判定を抑える実務的な手段です
- 営業・CSへ引き渡せる“行動ストーリー”が作れると、施策が評価されやすくなります
FAQ
初心者がつまずきやすい質問を中心に、断定せず、判断の軸・確認事項を提示します。
AI検索経由の流入は、参照元で必ず識別できますか?
常に必ず、とは言いにくいです。参照元が欠損したり、表記が揺れたりすることがあります。
そのため、識別は“できる範囲”で行い、確からしさラベル(確からしい/曖昧/不明)で扱うと運用が安定しやすいです。
- 参照元の欠損を前提にする
- 確からしさで段階化し、断定を避ける
まず最小で入れるべきイベントは何ですか?
中間行動の中で「段階が分かる」ものから絞るのが現実的です。
たとえば、定義、比較表、注意点、FAQ、問い合わせなど、意思決定の段階に対応する行動が選びやすいです。
- 段階が推定できるイベントを優先する
- 増やす前に、棚卸しで必要性を確認する
AI検索の“影響”は、クリックがなくても測れますか?
影響を断定するのは難しい場合がありますが、兆候として扱うことはできます。
たとえば再訪、共有、指名検索の増加などを、オルタナティブデータと合わせて“説明可能”にするイメージです。
- 再訪・共有を中間行動として拾う
- 問い合わせ要旨などの文脈データで補う
命名規則はどこまで厳密に作るべきですか?
厳密さより、意味が伝わり、引き継げることが重要になりやすいです。
カテゴリ_動詞_対象のように、読めば意味が分かる形に揃えると運用が続きやすいです。
- 短さより意味が残る命名を優先する
- 表記ゆれは名寄せ辞書で吸収する
レポートが複雑になり、関係者が納得しません。
レイヤー(入口・中間・成果)が混ざっている可能性があります。
まずレイヤーを分け、確からしさラベルで曖昧さを明示すると、納得感が上がりやすいです。
あわせて「不明」の増加や欠損を棚卸しで潰す運用を回すと、数字の信用が戻りやすいです。
- レイヤー分解(入口・中間・成果)
- 確からしさラベルで断定を避ける
- 棚卸しで欠損・例外を減らす
計測を改善にどうつなげれば良いですか?
「どの段階の情報が不足しているか」を中間行動で見立て、コンテンツ部品(定義・比較・注意点・FAQ)を改善する流れが分かりやすいです。
改善の優先度は、確からしさスコアや欠損の多い箇所から始めると運用負荷を抑えやすいです。
- 中間行動で不足段階を特定する
- 部品(定義・比較・注意点・FAQ)を改善する
- 欠損や例外が多い箇所から点検する
- AI検索由来は断定より、確からしさラベルで扱う方が現実的です
- 最小構成のイベントと命名規則が、運用の再現性を支えやすいです
- 棚卸し運用があると、計測が改善に接続しやすくなります

「IMデジタルマーケティングニュース」編集者として、最新のトレンドやテクニックを分かりやすく解説しています。業界の変化に対応し、読者の成功をサポートする記事をお届けしています。