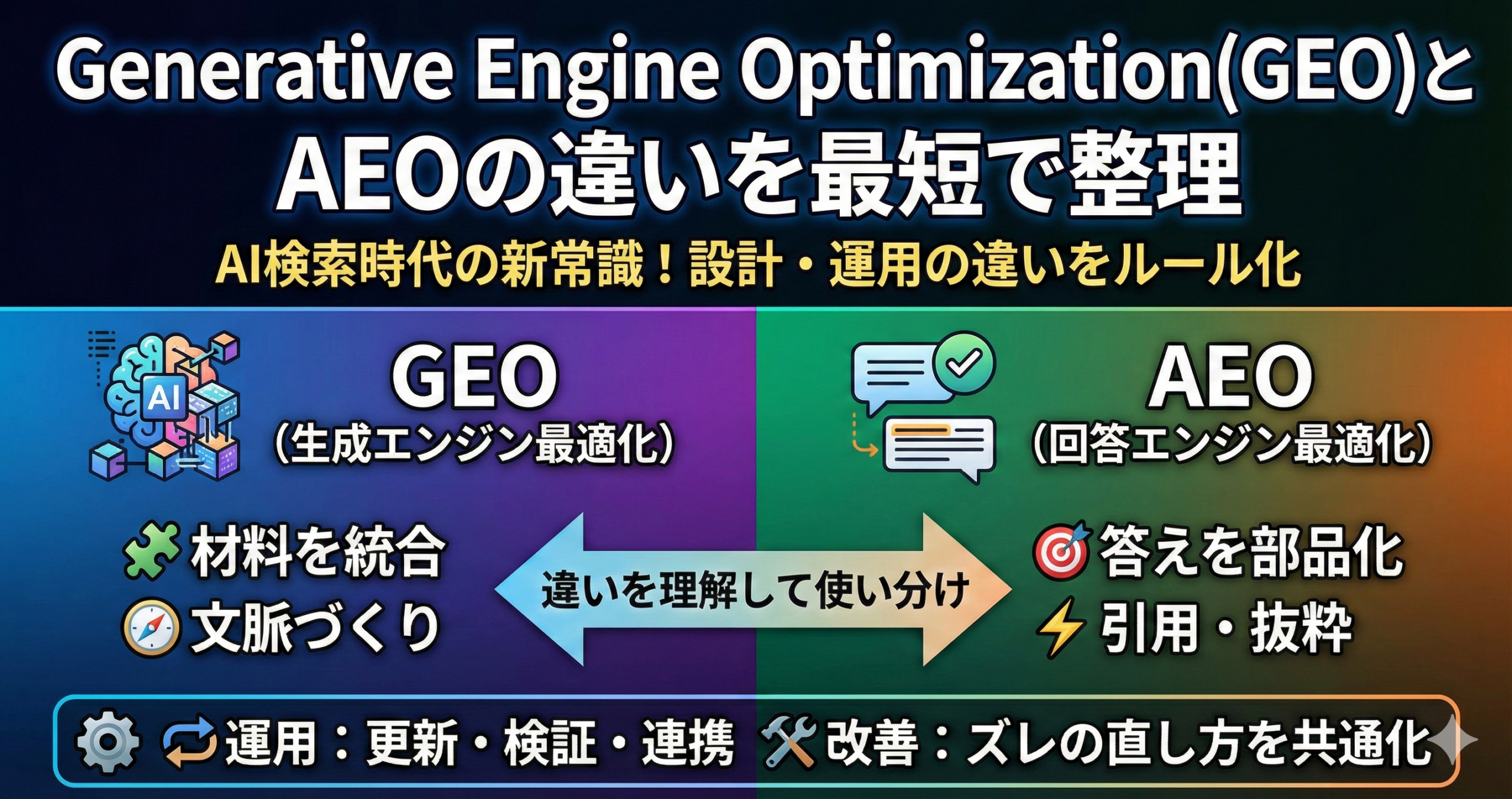
-2025-09-05T151236.591-320x180.png)

-7-320x180.png)





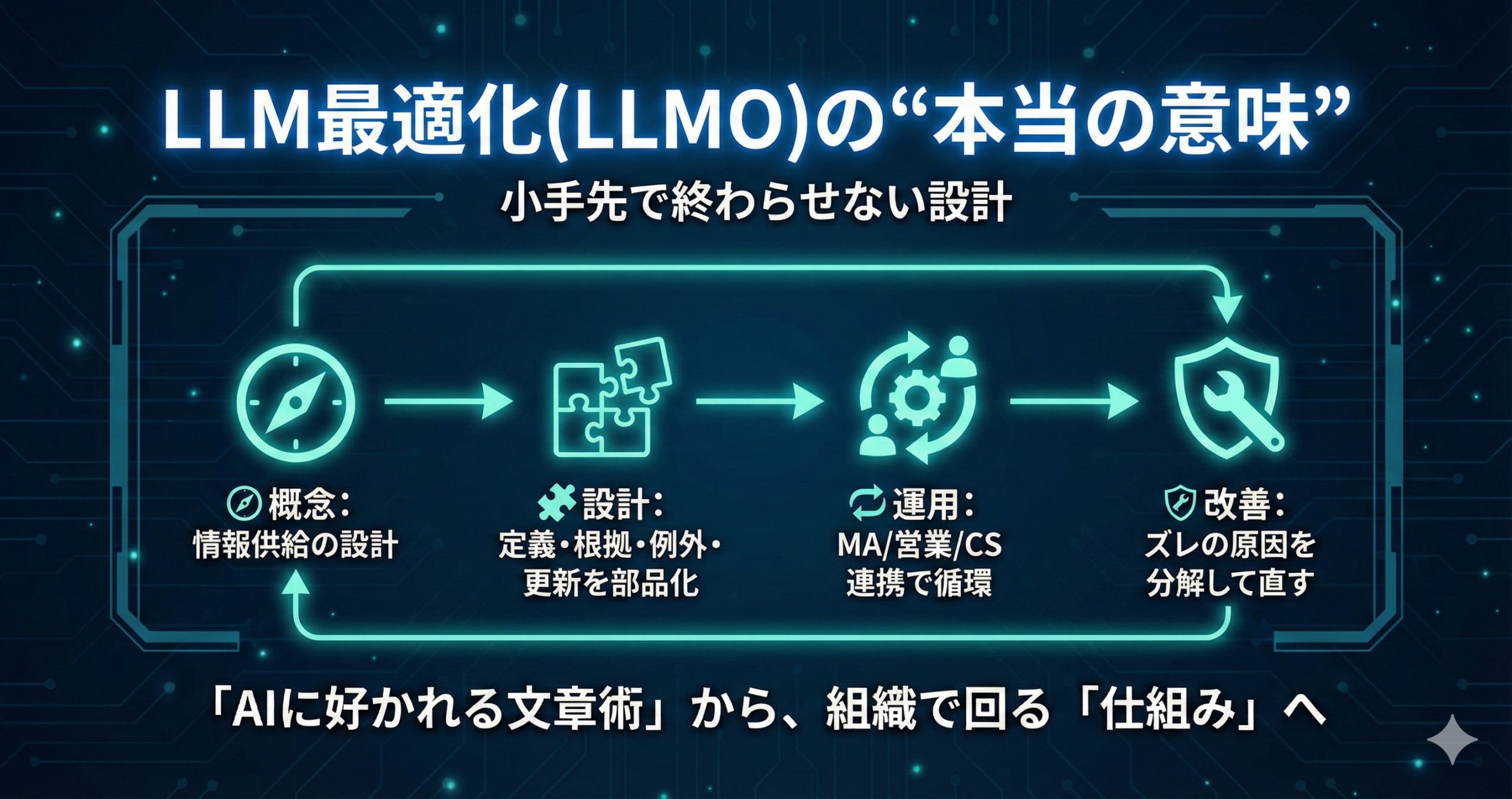
LLM最適化(LLMO)の“本当の意味”|小手先で終わらせない設計
LLMOは「AIに好かれる文章テクニック」として語られがちですが、実務で効くのは“文章の小手先”より、情報設計と運用設計が揃っていることです。
本記事では、LLMOを「AIの回答・要約・引用に使われやすい情報を、組織として継続的に供給する仕組み」として捉え直し、概念→設計→運用→改善まで落とします。


イントロダクション
“リスト運用が感覚頼みになりやすい理由”と“MA×データ×スコアリングで何が変わるか”を起点に、LLMOを小手先で終わらせない見取り図を作ります。
LLMOの話題が広がるほど、施策が「文章の整形」「見出しの工夫」「FAQの追加」だけで完結してしまうことがあります。 もちろん、それらが無意味というわけではありません。
ただ、現場で起きやすい失敗は「対策を増やしたのに、何が効いているのか分からない」「担当者が変わると品質が揺れる」といった“運用の不安定さ”です。
💬 現場あるある:LLMOが“感覚ゲーム”になってしまう
・AIに引用される日もあれば、されない日もある
・文章を変えたら良くなった気がするが、再現できない
・問い合わせは増えたが、ミスマッチも増えた気がする
こうした状況を整理する鍵は、「LLMOを“文章最適化”として扱わない」ことです。
実務上のLLMOは、AIが回答を作るときに参照しやすい情報を、継続的に供給・更新できる状態に近いです。 つまり、制作だけでなく、MA運用・データ整備・営業/CS連携まで含めた“仕組み”が必要になります。
LLMOで成果が出やすい組織は、文章がうまいというより、定義・根拠・例外・更新のルールが揃っていることが多いです。
そのルールを作ると、MA×データ×スコアリングの運用が変わり、リスト運用が“感覚”から“判断”に寄りやすくなります。
- LLMOが感覚頼みになる原因は「何を直すべきか」が分解されていないことです
- LLMOは“文章術”より“情報供給と更新の設計”として扱うと運用が安定しやすいです
- MA×データ×スコアリングと接続すると、改善のサイクルが回りやすくなります
概要
用語(MA / オルタナティブデータ / AIスコアリング)を噛み砕き、LLMOが「運用」単位で何を変えるのかを整理します。
LLMOは、検索施策の延長として理解されやすい一方で、実際は「問い合わせ前後のコミュニケーション」や「優先順位付け」にも影響します。
そのため、まずは運用でよく使う用語を揃え、LLMOがどこに作用するかを見える化します。
📩 MA(Marketing Automation)
見込み顧客との接点を運用する仕組みです。
LLMOで“理解が進んだ状態”の読者が増えると、次に出す情報や分岐の設計が重要になりやすいです。
🧩 オルタナティブデータ
自社内だけでは拾いにくい文脈情報(業界の動き、公開情報、技術・組織の変化など)です。
LLMOでは「前提条件の補強」「判断軸の提示」に寄与しやすいです。
🤖 AIスコアリング
複数のシグナルから、優先度や検討段階の推定に使う考え方です。
LLMOと相性がよいのは、“判定”ではなく並び替え・分岐・確認項目の提示として使うことです。
「LLMO=情報供給の設計」→(定義/根拠/例外/更新)→「AI回答」→「MA分岐」→「営業/CS」へつながるループ図
| 論点 | 小手先に寄る理解 | 設計としてのLLMO(本記事の捉え方) |
|---|---|---|
| 目的 | AIに引用される文章を作る | AIが参照できる“整った情報”を継続供給する |
| 主戦場 | 見出し・言い回し | 定義、根拠、条件、例外、更新、責任範囲 |
| 運用 | 担当者の工夫 | MA/営業/CSの質問回収→FAQ/辞書へ反映 |
| 改善 | 当たり外れを繰り返す | ズレの原因を分解し、直す場所を固定する |
- LLMOは“AIに見つかる”だけでなく、“AIが使える形で整う”ことに重心があります
- 定義・根拠・例外・更新を部品化すると、運用として再現しやすくなります
- MA/スコアリングと接続すると、LLMOが後工程の品質にも効きやすいです
利点
“精度”そのものより、“運用の再現性”が上がることを中心に、LLMOの利点を整理します。
LLMOを「文章の最適化」に閉じると、成果が出ても再現が難しく、施策が積み上がりません。
一方で、LLMOを設計として扱うと、制作・営業・CSを含む複数部門の会話が揃いやすくなります。
🧨 よくある課題
・属人化:書き手によって品質が揺れる
・優先順位のズレ:作るべきコンテンツが増え続ける
・温度感の誤判定:問い合わせの背景が読み違えられる
・更新が止まる:どこを直せばよいか分からない
🧰 改善されやすいポイント
・文章の型が揃い、レビューがしやすくなる
・“直す場所”が固定され、更新が回りやすくなる
・営業/CSの質問がFAQに戻り、誤解が減りやすくなる
・スコアの説明材料が揃い、運用が安定しやすい
たとえば、定義文のテンプレ、根拠の置き方、条件と例外の分け方、FAQの追加基準、更新責任などはルール化できます。
ルール化できる部分が増えるほど、成果が“担当者依存”になりにくいです。
引用は露出の一形態で、目的に対して有効かは別問題です。
実務では、引用・要約が増えた結果、問い合わせの質が変わる、営業工数が変わるなど、後工程の指標とセットで判断するとブレにくいです。
- LLMOを設計として扱うと、属人化を抑えやすいです
- “直す場所”が明確になり、更新と改善が回りやすくなります
- 露出の増減だけでなく、後工程(MA/営業/CS)の品質で評価しやすくなります
応用方法
BtoBを軸に、LLMOをMA×データ×スコアリングへ接続して運用する代表ユースケースを示します(BtoCの読み替えも短く添えます)。
LLMOの応用は「記事を作る」だけでは終わりません。
“AI回答で理解が進んだ人”が増えると、問い合わせ前の前提が変わり、MAの分岐や営業のヒアリングにも影響が出ます。
ここでは、運用単位で落としやすい使い方を整理します。
リード獲得後のスコアで配信シナリオを分岐
LLMOで整えた「定義・根拠・例外・FAQ」は、MAの分岐設計の材料になります。
たとえば、見出し(問い)を“関心テーマ”としてラベル化し、例外条件(適用しないケース)を分岐に使うと、配信の納得感が上がりやすいです。
✅ 分岐の作り方(概念レベル)
- 見出し=問い:関心テーマの分類に使う(例:導入、運用、リスク、社内調整)
- 条件と例外:シナリオ分岐のルールに落とす(例:体制、期間、対象範囲)
- FAQ:つまずきポイントを吸収し、離脱・誤解を減らす
- 根拠:営業資料・提案の“言い換え元”として再利用する
営業アプローチ順の最適化(判断基準として)
スコアで順番を決める場合でも、“なぜ高いのか”が説明できないと運用が崩れやすいです。
LLMOの設計で作った観点(関心テーマ、制約、検討段階)をラベルとして残すと、営業が判断しやすくなります。
いきなり自動判定に寄せるより、優先順位の候補を出し、確認項目(例外条件)を提示する形の方が受け入れられやすいことがあります。
LLMOの“例外”が、確認項目のテンプレとして役立ちます。
休眠掘り起こし(反応兆候の取り方)
休眠層は「状況が変わったときの問い」に反応しやすいことがあります。
LLMOで“条件が変わると判断が変わる”ポイントを整理しておくと、掘り起こしのメッセージに具体性が出やすいです。
いきなり高度な特徴量設計に進むより、まずはラベル設計から始めると安全です。
例:関心テーマ検討段階制約例外条件を固定し、各データをそこへ寄せます。
BtoCへの読み替え(短く)
BtoCでは、LLMOは「使い方」「トラブル」「比較」「注意点」をFAQとして厚くする方向に寄りやすいです。
ただし、押し出しすぎず、条件と例外を丁寧に置くと、誤解の削減につながりやすいです。
- LLMOは“記事”ではなく、MA分岐や営業判断の材料として再利用すると運用価値が上がりやすいです
- 見出し(問い)と例外条件は、ラベル化・分岐化に向いています
- スコアは判定より、並び替え・確認項目の提示として始めると整合が取りやすいです
導入方法
導入を「設計→データ→モデル→運用→改善→ガバナンス」に分解し、チェックリストで示します。小手先で終わらせないための“固定点”も明確にします。
LLMO導入で最初に作るべきものは、派手な施策ではなく「文章と情報のルール」です。
ルールがないままコンテンツを増やすと、後で整合を取るコストが膨らみやすいです。
ここでは、最小の固定点を中心にチェックします。
🧭 設計(目的/KPIと合意)
- 目的の言語化:引用されたいのか、理解を深めたいのか、問い合わせの質を整えたいのかを分ける
- KPIの定義:MQLの定義、優先度、営業SLA、例外(既存顧客・代理店など)の扱いを明確にする
- スコープ:全ページではなく、重点テーマ(質問が多い/誤解が多い/更新が多い)から着手する
- 編集ポリシー:断定しすぎない、条件と例外を置く、根拠の形を統一する
最低限、以下の部品はテンプレ化しておくと運用が回りやすいです。
「短い答え」→「根拠(箇条書き)」→「条件」→「例外」→「FAQ」→「更新メモ(変更点)」。
🧱 データ(名寄せ・欠損・更新頻度・粒度)
- 名寄せ:同じ概念が別名で書かれていないか(用語辞書で統一する)
- 欠損:条件・例外・対象範囲の抜けを点検対象にする
- 更新頻度:変わりやすい箇所(手順、仕様、用語)を“更新責任”として割り当てる
- 粒度:誰向けの前提か(初心者/実務者/意思決定者)を明確にし、混在を避ける
「LLMOの文章テンプレ(答え→根拠→条件→例外→FAQ→更新)」をカードで並べ、右側に「MA分岐」「営業SLA」へ矢印を伸ばした図
🤖 モデル(スコアの使い方:しきい値・分岐・例外)
- しきい値は固定しない:営業キャパや対応品質と合わせ、調整前提で扱う
- 分岐のルール:例外条件(対象外、前提不足)を先に定義し、誤判定コストを下げる
- 説明可能性:関心テーマ/検討段階/制約をラベルとして残し、理由が言える状態にする
- 小さく始める:まずは並び替えと確認項目の提示から始める
🔁 運用(運用担当・営業・CSの役割)
- 運用担当:テンプレの遵守、FAQ更新、用語辞書のメンテを担当する
- 営業:現場の質問と誤解を回収し、FAQ/条件/例外へ戻す
- CS:導入後のつまずきを構造化し、再発防止の文章へ反映する
- 共通:レビュー観点(答え/根拠/条件/例外/更新)を固定し、属人化を抑える
🧪 品質管理(ドリフト・誤判定・再学習)
- ドリフトの兆候:問い合わせの前提が変わる、比較軸が変わる、社内の説明が揺れる
- 誤判定の分解:データ不足、用語揺れ、例外欠落、運用ルール不備に分けて直す
- 再学習の考え方:トリガー型(体制変更、対象変更、メッセージ変更)で見直す
🛡️ リスクと注意点(ブラックボックス化・運用負荷・過学習っぽい兆候)
- ブラックボックス化:理由が言えないスコアは使いにくいので、ラベルで説明可能にする
- 運用負荷:全体最適より、重点テーマのテンプレ運用から広げる
- 過学習っぽい兆候:特定パターンだけ高く出る、現場実感と乖離する
- 責任範囲:スコアやAI出力は補助情報で、最終判断者を明文化する
- LLMOはテンプレ(答え→根拠→条件→例外→FAQ→更新)を固定すると運用が回りやすいです
- スコアは判定ではなく、並び替え・分岐・確認項目として使うと整合を取りやすいです
- 営業/CSの質問を回収して文章へ戻す循環が、設計としてのLLMOを支えます
未来展望
“AIスコアリングが一般化すると何が標準化されるか”を、運用/組織/データ観点で整理します(断定は避け、可能性として述べます)。
生成AIの利用が広がるほど、コンテンツは「読むもの」だけでなく「参照される部品」として扱われる場面が増えるかもしれません。
そのとき、LLMOは“文章の工夫”より、組織としての情報供給・更新の仕組みに近づきやすいです。
🔁 運用で標準化されやすいこと
・テンプレ(答え/根拠/条件/例外/FAQ/更新)の定着
・FAQの回収ループ(営業/CS→編集)
・更新トリガーの共通化(体制、提供範囲、説明の変更)
🏢 組織で標準化されやすいこと
・MQL定義と営業SLAの合意形成
・スコアの位置づけ(補助情報としての利用)
・説明責任(なぜそう判断したか)を支えるラベル設計
🧱 データで標準化されやすいこと
・用語辞書と同義語管理(言い換えの統一)
・粒度の統一(誰向けの前提か)
・例外条件の台帳化(対象外・前提不足の扱い)
🧭 迷いが残りやすいこと
・どこまで断定し、どこを条件扱いにするか
・誰の前提を“標準”にするか(全員の前提は揃えにくい)
・露出と成果の距離(評価会話の設計)
変化が早い領域ほど、完璧な記事を作るより、更新が回る仕組みを作る方が実務的です。
テンプレと回収ループがあると、知識が古くなるリスクを下げやすくなります。
- LLMOは、文章の工夫より「情報供給と更新の仕組み」として標準化されやすい可能性があります
- 営業/CSの質問をFAQへ戻す運用が、組織的なLLMOを支えやすいです
- 全体最適より、重点テーマから段階的に整える方が運用負荷を抑えやすいです
まとめ
本記事の要点を再整理し、PoC→運用適用の流れで「小さく始める」次アクションを提示します。
LLMOを文章テクニックとして扱うと、再現性が落ちやすいです。
定義・根拠・条件・例外・FAQ・更新のルールを部品化し、MA/営業/CSで回収して更新する仕組みにすると、運用として安定しやすくなります。
- LLMOは「AIに使われる情報を継続供給する仕組み」と捉えるとブレにくいです
- テンプレ(答え→根拠→条件→例外→FAQ→更新)を固定すると属人化を抑えやすいです
- 評価は露出だけでなく、後工程(MA/営業/CS)の品質とセットで行うと判断しやすいです
- スコアは判定より、並び替え・分岐・確認項目として使うと運用に落ちやすいです
- 改善は“ズレの原因”を分解して直すと、更新が止まりにくいです
🚶 次アクション(小さく始める:PoC→運用)
- 重点テーマを選び、テンプレに沿って「答え/根拠/条件/例外/FAQ/更新」を作る
- 営業・CSの質問を回収し、FAQと例外条件の台帳に戻す運用を先に作る
- MAで最小の分岐を作る(関心テーマ×例外条件)
- スコアは並び替えから開始し、説明ラベル(関心テーマ/制約/段階)を残す
免責:本記事は一般的な実務整理を目的とした内容です。組織体制・商材特性・利用ツールによって最適解は変わるため、現場の前提に合わせて調整してください。
FAQ
初心者がつまずきやすい質問を中心に、断定は避けつつ、判断の軸・確認事項を提示します。
LLMOはSEOと置き換わるものですか?
検索での到達に加え、AIの回答・要約・引用の形で情報が使われる場面が増えると、文章だけでなく「定義・根拠・例外・更新」の設計が重要になりやすいです。
LLMOは結局、見出しやFAQを増やすことですか?
「短い答え」「根拠」「条件」「例外」「更新メモ」をセットにして、営業/CSの質問を回収して更新する仕組みにすると、運用として安定しやすくなります。
何から始めると、小手先で終わりにくいですか?
同時に、営業/CSの質問を回収してFAQへ戻すループを用意すると、改善が止まりにくいです。
どんなデータが必要ですか?(文章以外も含めて)
例:関心テーマ(どの問いに関心があるか)、検討段階、制約(体制/期間/対象)、例外条件(対象外/前提不足)などです。
これらを揃えると、MA分岐やスコアの説明材料になります。
精度が不安です。AIスコアリングは危険ではありませんか?
まずは並び替えと確認項目の提示から始め、例外条件を先に定義して“救う”運用にすると、現場の受け入れが進みやすいです。
重要なのは、理由が言えるラベル(関心テーマ/制約/段階)を残すことです。
改善はどこを見ればよいですか?
例:用語揺れ、条件/例外の欠落、根拠不足、更新遅れ、運用ルール不備などに分け、直す場所を固定します。
直す場所が固定されるほど、改善が属人化しにくくなります。
- LLMOは“見出しやFAQの追加”だけでなく、更新まで含む仕組みにすると安定しやすいです
- ラベル設計(関心テーマ/制約/段階/例外)は、MAとスコアリング接続の基盤になります
- 改善は原因を分解し、直す場所を固定すると進めやすいです
免責:本記事は一般論としての実務整理です。組織の体制・商材・顧客特性・利用ツールにより最適な設計は変わるため、前提に合わせて調整してください。

「IMデジタルマーケティングニュース」編集者として、最新のトレンドやテクニックを分かりやすく解説しています。業界の変化に対応し、読者の成功をサポートする記事をお届けしています。